We introduce the new concept of sparsified genomics where we systematically exclude a large number of bases from genomic sequences and enable the processing of the sparsified, shorter genomic sequence while maintaining the same or better accuracy than that of processing non-sparsified sequences. We deomonstrate significant benefits over sttate-of-the-art read mapper, minimap2.
Described by Alser et al. (preliminary version at https://arxiv.org/abs/2211.08157).
Genome-on-Diet is multithreaded and it exploits modern machines with AVX-512 support for high performance. When users do NOT have such machines, Genome-on-Diet still works efficiently on traditional machines with SSE and non-SIMD machines. When building Genome-on-Diet using make command, you will recieve four executable files (Check here for details). Genome-on-Diet is debugged and tested using gcc 12.1.0-16.
- Installation & General usage
- Use Cases
- Key Idea
- Benefits of Genome-on-Diet
- Using Genome-on-Diet
- Directory Structure
- Getting help
- Citing Genome-on-Diet
git clone https://github.com/CMU-SAFARI/Genome-on-Diet
make -C Genome-on-Diet/GDiet-ShortReads
make -C Genome-on-Diet/GDiet-LongReads
#Wihout AVX-512 acceleraion:
GDiet [options] <target.fa>|<target.idx> [query.fa] [...]
#With AVX-512 acceleration:
GDiet_avx [options] <target.fa>|<target.idx> [query.fa] [...]
#With AVX-512-accelerated Indexing/Sketching:
GDiet_sketch_avx [options] <target.fa>|<target.idx> [query.fa] [...]
#With AVX-512-accelerated Sequencing Alignment:
GDiet_ksw2_avx [options] <target.fa>|<target.idx> [query.fa] [...]# Illumina sequences
Genome-on-Diet/GDiet-ShortReads/GDiet_avx -t 1 -ax sr -Z 10 -W 2 -i 2 -k 21 -w 11 -N 1 -r 0.05,150,200 -n 0.95,0.3 -s 100 --AF_max_loc 2 --secondary=yes -a -o Genome-on-Diet-GRCh38-Illumina_k21w11.sam ../Data/GCA_000001405.15_GRCh38_no_alt_analysis_set.fasta ../Data/D1_S1_L001_R1_001-017.fastq
# HiFi sequences
Genome-on-Diet/GDiet-LongReads/GDiet_avx -t 1 -ax map-hifi -Z 10 -W 2 -i 0.2 -k 19 -w 19 -N 1 -r 1000 --vt_dis=650 --vt_nb_loc=5 --vt_df1=0.0106 --vt_df2=0.2 -s 400 --vt_cov 0.04 --max_min_gap=4000 --vt_f=0.04 --sort=merge --frag=no -F200,1 --secondary=yes -a -o Genome-on-Diet-GRCh38-HiFi_k19w19.sam ../Data/GCA_000001405.15_GRCh38_no_alt_analysis_set.fasta ../Data/m64011_190830_220126.fastq
# ONT sequences
Genome-on-Diet/GDiet-LongReads/GDiet_avx -t 1 -ax map-ont -Z 10 -W 2 -i 0.2 -k 15 -w 10 -N 1 -r 1300 --vt_dis=1000 --vt_nb_loc=3 --vt_df1=0.007 --vt_df2=0.007 --max_min_gap=4000 --vt_f=0.04 -s 35000 --vt_cov 0.3 --sort=merge --frag=no -F200,1 --secondary=yes -a -o Genome-on-Diet-GRCh38-ONT_k15w10.sam ../Data/GCA_000001405.15_GRCh38_no_alt_analysis_set.fasta ../Data/HG002_ONT-UL_GIAB_20200204_1000filtered_2Mreads.fastqWe now need more than ever to catalyze and greatly accelerate genomic analyses by addressing the four critical limitations. Our goal is to enable ultra-fast and highly-efficient indexing and seeding steps in various genomic analyses so that pre-building genome indexes for each genome assembly is no longer a requirement for quickly and directly running large-scale genomic analyses using large genomes and various versions of genome assembly.
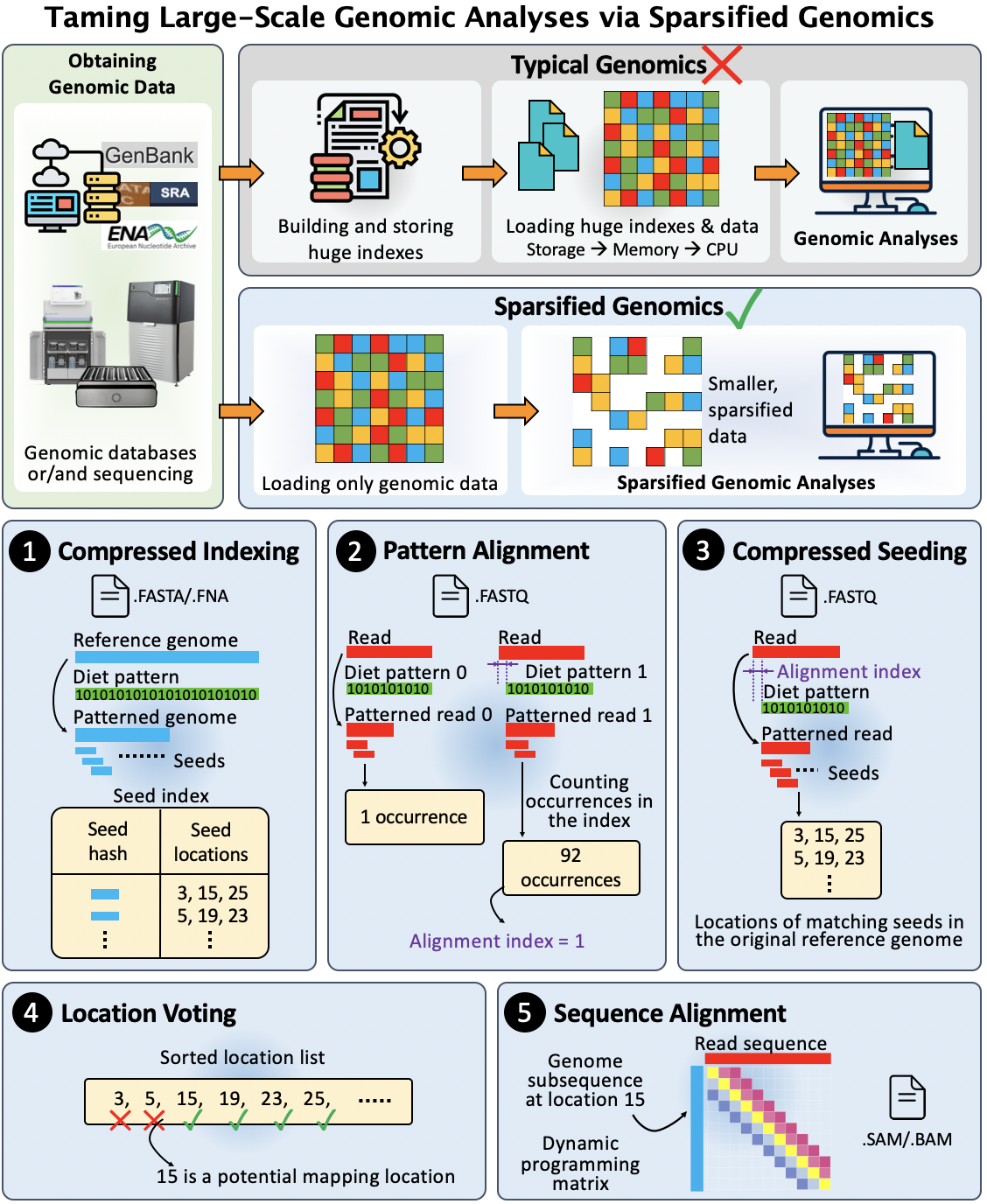
We introduce the new concept of sparsified genomics where we systematically exclude a large number of bases from genomic sequences and enable the processing of the sparsified, shorter genomic sequence while maintaining the same or better accuracy than that of processing non-sparsified sequences. We exploit redundancy in genomic sequences to eliminate some regions in the genomic sequences to reduce the input workload of each step of genomic analysis and accelerate overall performance (check te figure below). To demonstrate the benefits of sparsified genomics in real genomic applications, we introduce Genome-on-Diet, the first highly parallel, memory-frugal, and accurate framework for sparsifying genomic sequences.
Genome-on-Diet is based on four major ideas.
- Using a repeating pattern sequence to decide on which base in the genomic sequence should be excluded and which one should be included. The pattern sequence is a user-defined shortest repeating substring that represents included and excluded bases by 1’s and 0’s, respectively. Genome-on-Diet provides lossless compression to genomic sequences as it only manipulates a copy of the genomic sequence that is used for the initial steps of an analysis, such as indexing and seeding. The original genomic sequence is still maintained for performing accuracy-critical steps of an analysis, such as base-level sequence alignment where all bases must be accounted for.
- Inferring at which location of the query sequence the pattern should be applied in order to correctly match the included bases of the query sequence with the included bases of the target sequences. Applying the pattern always starting from the first base of the read sequence can lead to poor results due to a possible lack of seed matches.
- Providing a highly parallel and highly optimized implementation using modern single-instruction multiple-data (SIMD) instructions employed in modern microprocessors.
- Introducing four key optimization strategies for making Genome-on-Diet highly parallel, efficient, and accurate. All parameters and optimizations can be conveniently configured, enabled, and disabled using input parameter values entered in the command line of Genome-on-Diet.
Sparsifying genomic sequences makes large-scale analyses feasible and efficient. The use of ‘1110’, ‘110’, ‘10’, and ‘100’ patterns accelerates the analyses we evaluated by 1.3x, 1.4x, 1.9x, and 2.7x, respectively, showing a reduction in the execution time by almost 1/4, 1/3, 1/2, and 2/3, respectively. This demonstrates that the execution time scales linearly with the number of zeros determined in the pattern sequence. The use of ‘1110’, ‘110’, ‘10’, and ‘100’ patterns also directly reduces the size of the index by 1/4, 1/3, 1/2, and 2/3, respectively.
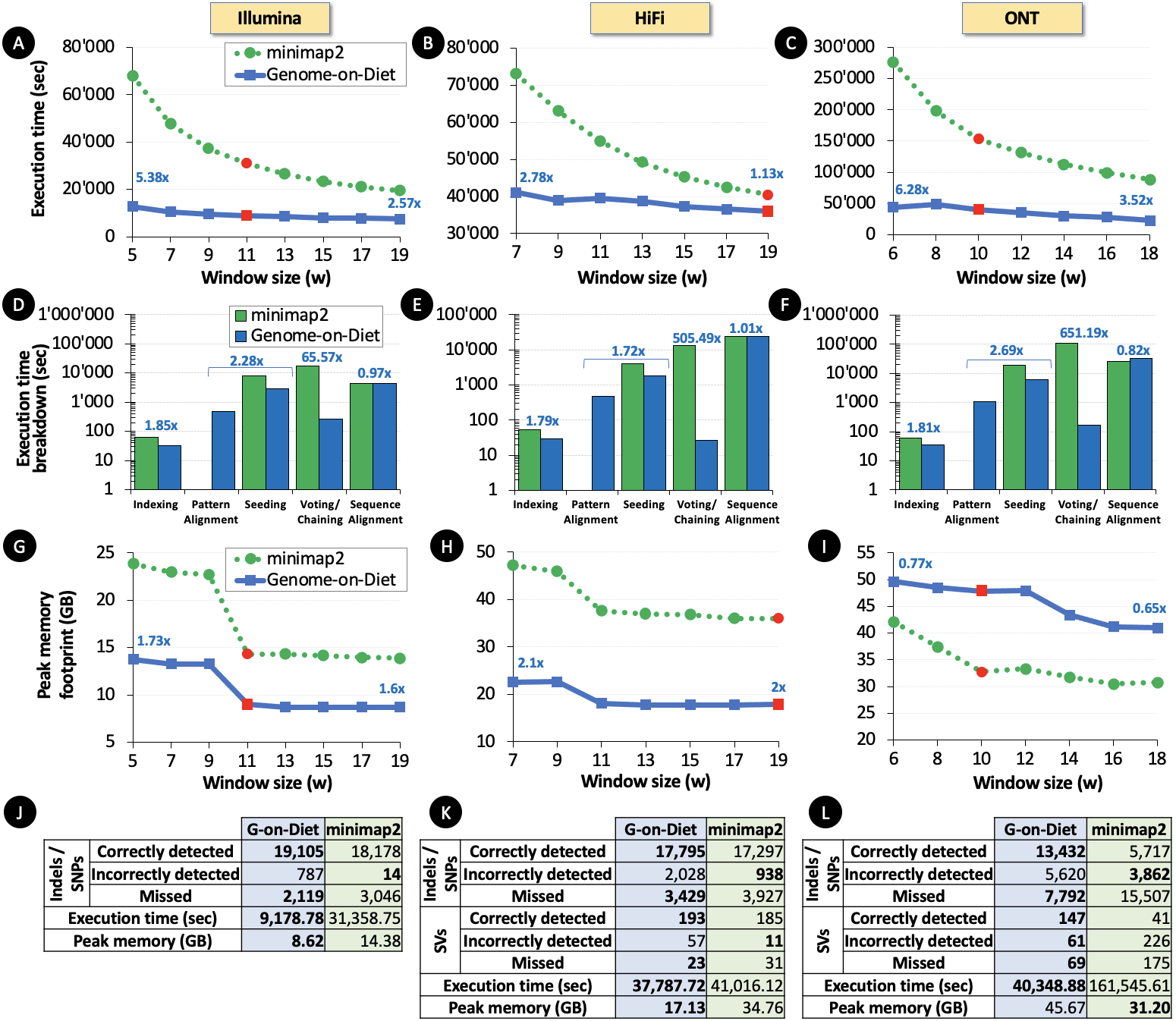
Sparsifying genomic sequences greatly accelerates state-of-the-art read mappers by 2.57-5.38x, 1.13-2.78x, and 3.52-6.28x using real Illumina, HiFi, and ONT reads, respectively, while providing a higher number of mapped reads with the highest mapping quality and more detected indels and complex structural variations. Sparsifying genomic sequences makes containment search through very large genomes and very large databases 72.7-75.88x faster and 723.3x more space-efficient than searching through non-sparsified genomic sequences. Sparsifying genomic sequences enables robust microbiome discovery by providing 54.15-61.88x faster and 720x more space-efficient taxonomic profiling of metagenomic samples.
The concept of sparsified genomics can be implemented and leveraged using different implementations and algorithms. We introduce one way to implement sparsified genomics using highly-efficient and well-optimized framework, called Genome-on-Diet. The Genome-on-Diet framework is a five-step procedure: compressed indexing, pattern alignment, compressed seeding, location voting, and sequence alignment. These steps can be used individually or collectively together depending on the target genomic analysis.
Genome-on-Diet-master
├───1. Data
└───2. GDiet-LongReads
└───3. GDiet-ShortReads
├───4. ReproducibleEvaluation
└───5. ReadMapping
├───6. RawResults
├───7. Figures
- In the "Data" directory, you will find a description of the sequencing reads and metagenomic reads that we used in our evaluation. You will also find details on how to obtain the reference genomes and RefSeq database that we used in our evaluation. This enables you to use the scripts we have in the "ReproducibleEvaluation" directory to reproduce the exact same experimental evaluations.
- In the "GDiet-LongReads" directory, you will find the source code of the Genome-on-Diet implementation for long reads, such as CLR, HiFi, and ONT reads. We use the source code of minimap2 as a baseline, where we applied our changes directly to minimap2. This enables researchers that are familiar with the source code of minimap2 to be also familiar with the source code of Genome-on-Diet with minimal efforts.
- In the "GDiet-ShortReads" directory, you will find the source code of the Genome-on-Diet implementation for shortt reads, such as Illumina reads. We use the source code of minimap2 as a baseline, where we applied our changes directly to minimap2. This enables researchers that are familiar with the source code of minimap2 to be also familiar with the source code of Genome-on-Diet with minimal efforts.
- In the "ReproducibleEvaluation" directory, you will find all shell scripts and commands we used to run the experimental evaluations we presented in the paper.
- In the "RawResults" directory, you will find all raw results and exact values that we presented in the paper.
- In the "Figures" directory, you will find the highh-quality figures that we included in the paper.
If you have any suggestion for improvement, new applications, or collaboration, please contact alserm at ethz dot ch If you encounter bugs or have further questions or requests, you can raise an issue at the issue page.
If you use Genome-on-Diet in your work, please cite:
Mohammed Alser, Julien Eudine, and Onur Mutlu. "Taming Large-Scale Genomic Analyses via Sparsified Genomics" (2022). link
Below is bibtex format for citation.
@article{Genome-on-Diet2022,
author = {Alser, Mohammed and Eudine, Julien and Mutlu, Onur},
title = "{Taming Large-Scale Genomic Analyses via Sparsified Genomics}",
year = {2022},
}