If you just want to use metadata ingestion, check the user-centric guide. This document is for developers who want to develop and possibly contribute to the metadata ingestion framework.
Also take a look at the guide to adding a source.
- Python 3.8+ must be installed in your host environment.
- Java 17 (gradle won't work with newer or older versions)
- On Debian/Ubuntu:
sudo apt install python3-dev python3-venv - On Fedora (if using LDAP source integration):
sudo yum install openldap-devel
From the repository root:
cd metadata-ingestion
../gradlew :metadata-ingestion:installDev
source venv/bin/activate
datahub version # should print "DataHub CLI version: unavailable (installed in develop mode)"From the repository root:
cd metadata-ingestion-modules/airflow-plugin
../../gradlew :metadata-ingestion-modules:airflow-plugin:installDev
source venv/bin/activate
datahub version # should print "DataHub CLI version: unavailable (installed in develop mode)"
# start the airflow web server
export AIRFLOW_HOME=~/airflow
airflow webserver --port 8090 -d
# start the airflow scheduler
airflow scheduler
# access the airflow service and run any of the DAG
# open http://localhost:8090/
# select any DAG and click on the `play arrow` button to start the DAG
# add the debug lines in the codebase, i.e. in ./src/datahub_airflow_plugin/datahub_listener.py
logger.debug("this is the sample debug line")
# run the DAG again and you can see the debug lines in the task_run log at,
#1. click on the `timestamp` in the `Last Run` column
#2. select the task
#3. click on the `log` optionP.S. if you are not able to see the log lines, then restart the
airflow schedulerand rerun the DAG
From the repository root:
cd metadata-ingestion-modules/dagster-plugin
../../gradlew :metadata-ingestion-modules:dagster-plugin:installDev
source venv/bin/activate
datahub version # should print "DataHub CLI version: unavailable (installed in develop mode)"From the repository root:
cd metadata-ingestion-modules/prefect-plugin
../../gradlew :metadata-ingestion-modules:prefect-plugin:installDev
source venv/bin/activate
datahub version # should print "DataHub CLI version: unavailable (installed in develop mode)"From the repository root:
cd metadata-ingestion-modules/gx-plugin
../../gradlew :metadata-ingestion-modules:gx-plugin:installDev
source venv/bin/activate
datahub version # should print "DataHub CLI version: unavailable (installed in develop mode)"From the repository root:
cd metadata-ingestion-modules/dagster-plugin
../../gradlew :metadata-ingestion-modules:dagster-plugin:installDev
source venv/bin/activate
datahub version # should print "DataHub CLI version: unavailable (installed in develop mode)"Common issues (click to expand):
datahub command not found with PyPI install
If you've already run the pip install, but running datahub in your command line doesn't work, then there is likely an issue with your PATH setup and Python.
The easiest way to circumvent this is to install and run via Python, and use python3 -m datahub in place of datahub.
python3 -m pip install --upgrade acryl-datahub
python3 -m datahub --helpWheel issues e.g. "Failed building wheel for avro-python3" or "error: invalid command 'bdist_wheel'"
This means Python's wheel is not installed. Try running the following commands and then retry.
pip install --upgrade pip wheel setuptools
pip cache purgeFailure to install confluent_kafka: "error: command 'x86_64-linux-gnu-gcc' failed with exit status 1"
This sometimes happens if there's a version mismatch between the Kafka's C library and the Python wrapper library. Try running pip install confluent_kafka==1.5.0 and then retrying.
Conflict: acryl-datahub requires pydantic 1.10
The base acryl-datahub package supports both Pydantic 1.x and 2.x. However, some of our specific sources require Pydantic 1.x because of transitive dependencies.
If you're primarily using acryl-datahub for the SDKs, you can install acryl-datahub and some extras, like acryl-datahub[sql-parser], without getting conflicts related to Pydantic versioning.
We recommend not installing full ingestion sources into your main environment (e.g. avoid having a dependency on acryl-datahub[snowflake] or other ingestion sources).
Instead, we recommend using UI-based ingestion or isolating the ingestion pipelines using virtual environments. If you're using an orchestrator, they often have first-class support for virtual environments - here's an example for Airflow.
The syntax for installing plugins is slightly different in development. For example:
- pip install 'acryl-datahub[bigquery,datahub-rest]'
+ pip install -e '.[bigquery,datahub-rest]'
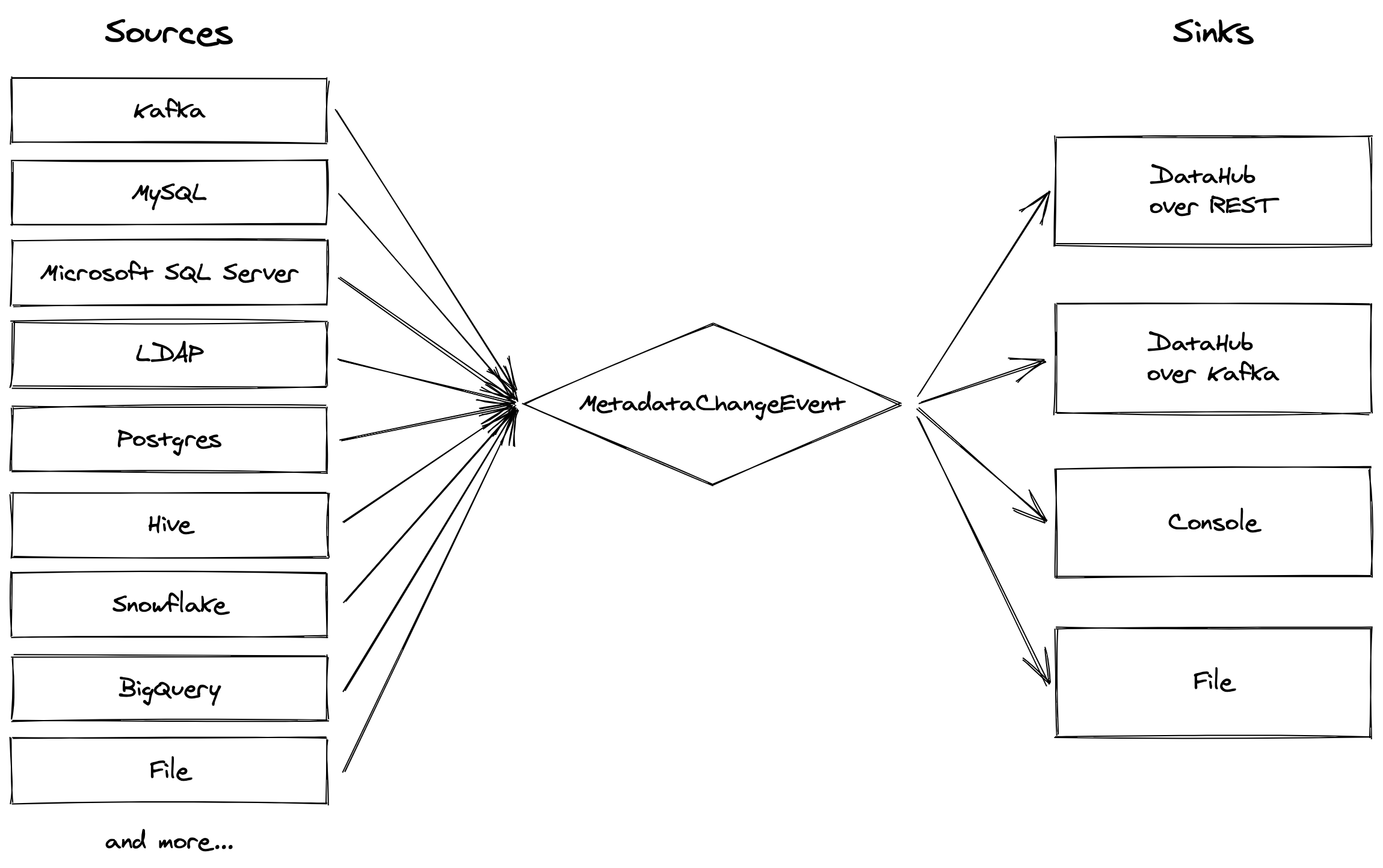
The architecture of this metadata ingestion framework is heavily inspired by Apache Gobblin (also originally a LinkedIn project!). We have a standardized format - the MetadataChangeEvent - and sources and sinks which respectively produce and consume these objects. The sources pull metadata from a variety of data systems, while the sinks are primarily for moving this metadata into DataHub.
- The CLI interface is defined in entrypoints.py and in the cli directory.
- The high level interfaces are defined in the API directory.
- The actual sources and sinks have their own directories. The registry files in those directories import the implementations.
- The metadata models are created using code generation, and eventually live in the
./src/datahub/metadatadirectory. However, these files are not checked in and instead are generated at build time. See the codegen script for details. - Tests live in the
testsdirectory. They're split between smaller unit tests and larger integration tests.
We use black, isort, flake8, and mypy to ensure consistent code style and quality.
# Assumes: pip install -e '.[dev]' and venv is activated
black src/ tests/
isort src/ tests/
flake8 src/ tests/
mypy src/ tests/or you can run from root of the repository
./gradlew :metadata-ingestion:lintFixSome other notes:
- Prefer mixin classes over tall inheritance hierarchies.
- Write type annotations wherever possible.
- Use
typing.Protocolto make implicit interfaces explicit. - If you ever find yourself copying and pasting large chunks of code, there's probably a better way to do it.
- Prefer a standalone helper method over a
@staticmethod. - You probably should not be defining a
__hash__method yourself. Using@dataclass(frozen=True)is a good way to get a hashable class. - Avoid global state. In sources, this includes instance variables that effectively function as "global" state for the source.
- Avoid defining functions within other functions. This makes it harder to read and test the code.
- When interacting with external APIs, parse the responses into a dataclass rather than operating directly on the response object.
The vast majority of our dependencies are not required by the "core" package but instead can be optionally installed using Python "extras". This allows us to keep the core package lightweight. We should be deliberate about adding new dependencies to the core framework.
Where possible, we should avoid pinning version dependencies. The acryl-datahub package is frequently used as a library and hence installed alongside other tools. If you need to restrict the version of a dependency, use a range like >=1.2.3,<2.0.0 or a negative constraint like >=1.2.3, !=1.2.7 instead. Every upper bound and negative constraint should be accompanied by a comment explaining why it's necessary.
Caveat: Some packages like Great Expectations and Airflow frequently make breaking changes. For such packages, it's ok to add a "defensive" upper bound with the current latest version, accompanied by a comment. It's critical that we revisit these upper bounds at least once a month and broaden them if possible.
We use pydantic to define the ingestion configs. In order to ensure that the configs are consistent and easy to use, we have a few guidelines:
- Most important point: we should match the terminology of the source system. For example, snowflake shouldn’t have a
host_port, it should have anaccount_id. - We should prefer slightly more verbose names when the alternative isn’t descriptive enough. For example
client_idortenant_idover a bareidandaccess_secretover a baresecret. - AllowDenyPatterns should be used whenever we need to filter a list. The pattern should always apply to the fully qualified name of the entity. These configs should be named
*_pattern, for exampletable_pattern. - Avoid
*_onlyconfigs likeprofile_table_level_onlyin favor ofprofile_table_levelandprofile_column_level.include_tablesandinclude_viewsare a good example.
- All configs should have a description.
- When using inheritance or mixin classes, make sure that the fields and documentation is applicable in the base class. The
bigquery_temp_table_schemafield definitely shouldn’t be showing up in every single source’s profiling config! - Set reasonable defaults!
- The configs should not contain a default that you’d reasonably expect to be built in. As a bad example, the Postgres source’s
schema_patternhas a default deny pattern containinginformation_schema. This means that if the user overrides the schema_pattern, they’ll need to manually add the information_schema to their deny patterns. This is a bad, and the filtering should’ve been handled automatically by the source’s implementation, not added at runtime by its config.
- The configs should not contain a default that you’d reasonably expect to be built in. As a bad example, the Postgres source’s
- Use a single pydantic validator per thing to validate - we shouldn’t have validation methods that are 50 lines long.
- Use
SecretStrfor passwords, auth tokens, etc. - When doing simple field renames, use the
pydantic_renamed_fieldhelper. - When doing field deprecations, use the
pydantic_removed_fieldhelper. - Validator methods must only throw ValueError, TypeError, or AssertionError. Do not throw ConfigurationError from validators.
- Set
hidden_from_docsfor internal-only config flags. However, needing this often indicates a larger problem with the code structure. The hidden field should probably be a class attribute or an instance variable on the corresponding source.
# Follow standard install from source procedure - see above.
# Install, including all dev requirements.
pip install -e '.[dev]'
# For running integration tests, you can use
pip install -e '.[integration-tests]'
# Run the full testing suite
pytest -vv
# Run unit tests.
pytest -m 'not integration'
# Run Docker-based integration tests.
pytest -m 'integration'
# You can also run these steps via the gradle build:
../gradlew :metadata-ingestion:lint
../gradlew :metadata-ingestion:lintFix
../gradlew :metadata-ingestion:testQuick
../gradlew :metadata-ingestion:testFull
../gradlew :metadata-ingestion:check
# Run all tests in a single file
../gradlew :metadata-ingestion:testSingle -PtestFile=tests/unit/test_bigquery_source.py
# Run all tests under tests/unit
../gradlew :metadata-ingestion:testSingle -PtestFile=tests/unitIf you made some changes that require generating new "golden" data files for use in testing a specific ingestion source, you can run the following to re-generate them:
pytest tests/integration/<source>/<source>.py --update-golden-filesFor example,
pytest tests/integration/dbt/test_dbt.py --update-golden-filesFor the Airflow plugin, we use tox to test across multiple sets of dependencies.
cd metadata-ingestion-modules/airflow-plugin
# Run all tests.
tox
# Run a specific environment.
# These are defined in the `tox.ini` file
tox -e py310-airflow26
# Run a specific test.
tox -e py310-airflow26 -- tests/integration/test_plugin.py
# Update all golden files.
tox -- --update-golden-files
# Update golden files for a specific environment.
tox -e py310-airflow26 -- --update-golden-files