Releases: JohnSnowLabs/nlu
1 line to visualizations for dependency trees, entity relationships, resolution, assertion, NER and new models for Afrikaans, Welsh, Maltese, Tamil, and Vietnamese - John Snow Labs NLU 3.0.1 for Python
NLU 3.0.1 Release Notes
We are very excited to announce NLU 3.0.1 has been released!
This is one of the most visually appealing releases, with the integration of the Spark-NLP-Display library and visualizations for dependency trees, entity resolution, entity assertion, relationship between entities and named entity recognition. In addition to this, the schema of how columns are named by NLU has been reworked and all 140+ tutorial notebooks have been updated to reflect the latest changes in NLU 3.0.0+
Finally, new multilingual models for Afrikaans, Welsh, Maltese, Tamil, andVietnamese are now available.
New Features and Enhancements
- 1 line to visualization for
NER,Dependency,Resolution,AssertionandRelationvia Spark-NLP-Display integration - Improved column naming schema
- Over 140 + NLU tutorial Notebooks updated and improved to reflect latest changes in NLU 3.0.0 +
- New multilingual models for
Afrikaans,Welsh,Maltese,Tamil, andVietnamese - Enhanced offline loading
NLU visualization
The latest NLU release integrated the beautiful Spark-NLP-Display package visualizations. You do not need to worry about installing it, when you try to visualize something, NLU will check if
Spark-NLP-Display is installed, if it is missing it will be dynamically installed into your python executable environment, so you don't need to worry about anything!
See the visualization tutorial notebook and visualization docs for more info.
NER visualization
Applicable to any of the 100+ NER models! See here for an overview
nlu.load('ner').viz("Donald Trump from America and Angela Merkel from Germany don't share many oppinions.")
Dependency tree visualization
Visualizes the structure of the labeled dependency tree and part of speech tags
nlu.load('dep.typed').viz("Billy went to the mall")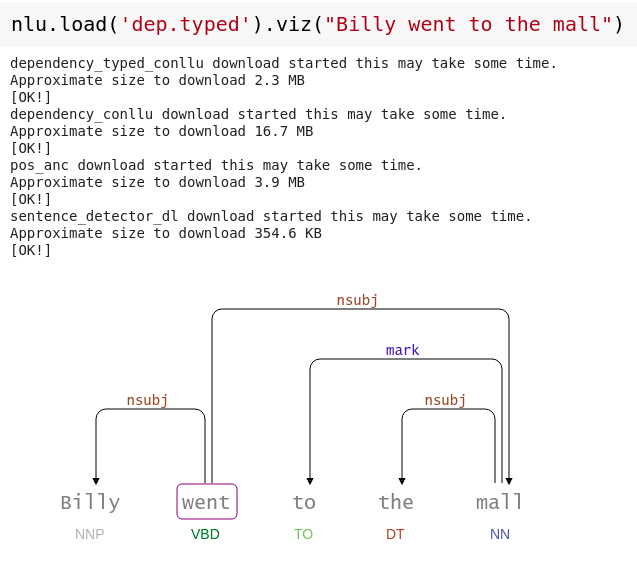
#Bigger Example
nlu.load('dep.typed').viz("Donald Trump from America and Angela Merkel from Germany don't share many oppinions but they both love John Snow Labs software")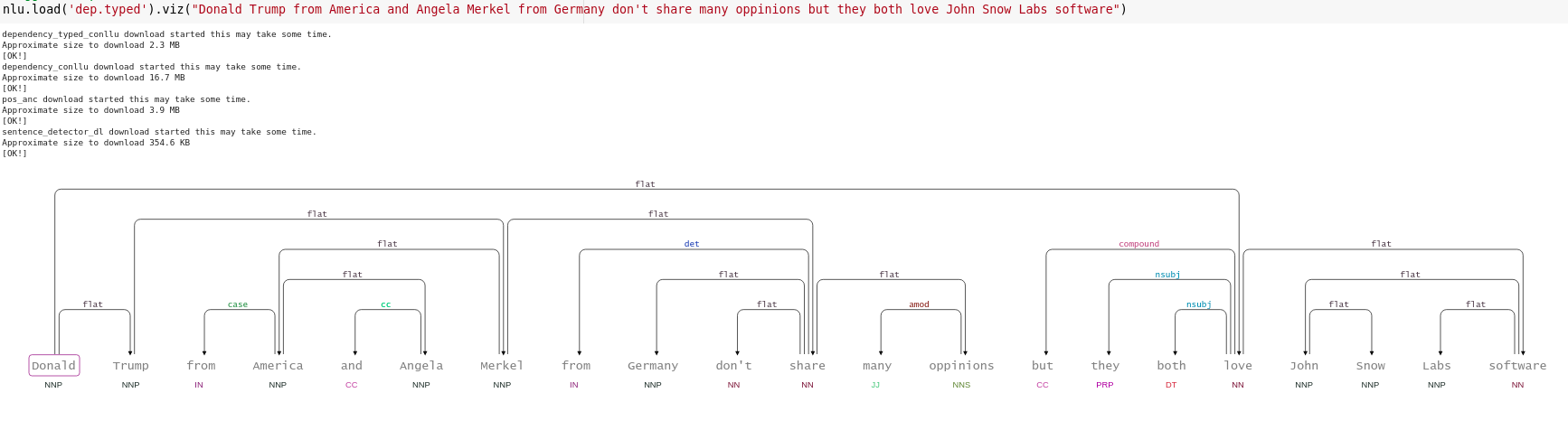
Assertion status visualization
Visualizes asserted statuses and entities.
Applicable to any of the 10 + Assertion models! See here for an overview
nlu.load('med_ner.clinical assert').viz("The MRI scan showed no signs of cancer in the left lung")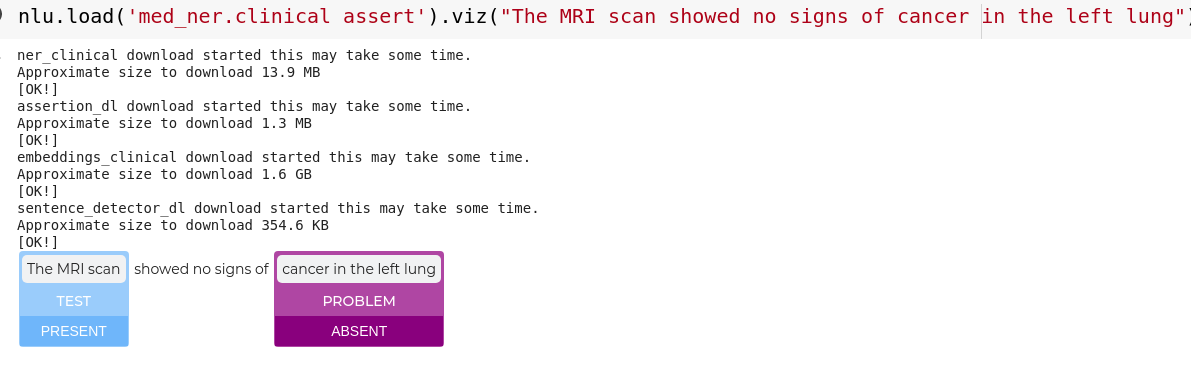
#bigger example
data ='This is the case of a very pleasant 46-year-old Caucasian female, seen in clinic on 12/11/07 during which time MRI of the left shoulder showed no evidence of rotator cuff tear. She did have a previous MRI of the cervical spine that did show an osteophyte on the left C6-C7 level. Based on this, negative MRI of the shoulder, the patient was recommended to have anterior cervical discectomy with anterior interbody fusion at C6-C7 level. Operation, expected outcome, risks, and benefits were discussed with her. Risks include, but not exclusive of bleeding and infection, bleeding could be soft tissue bleeding, which may compromise airway and may result in return to the operating room emergently for evacuation of said hematoma. There is also the possibility of bleeding into the epidural space, which can compress the spinal cord and result in weakness and numbness of all four extremities as well as impairment of bowel and bladder function. However, the patient may develop deeper-seated infection, which may require return to the operating room. Should the infection be in the area of the spinal instrumentation, this will cause a dilemma since there might be a need to remove the spinal instrumentation and/or allograft. There is also the possibility of potential injury to the esophageus, the trachea, and the carotid artery. There is also the risks of stroke on the right cerebral circulation should an undiagnosed plaque be propelled from the right carotid. She understood all of these risks and agreed to have the procedure performed.'
nlu.load('med_ner.clinical assert').viz(data)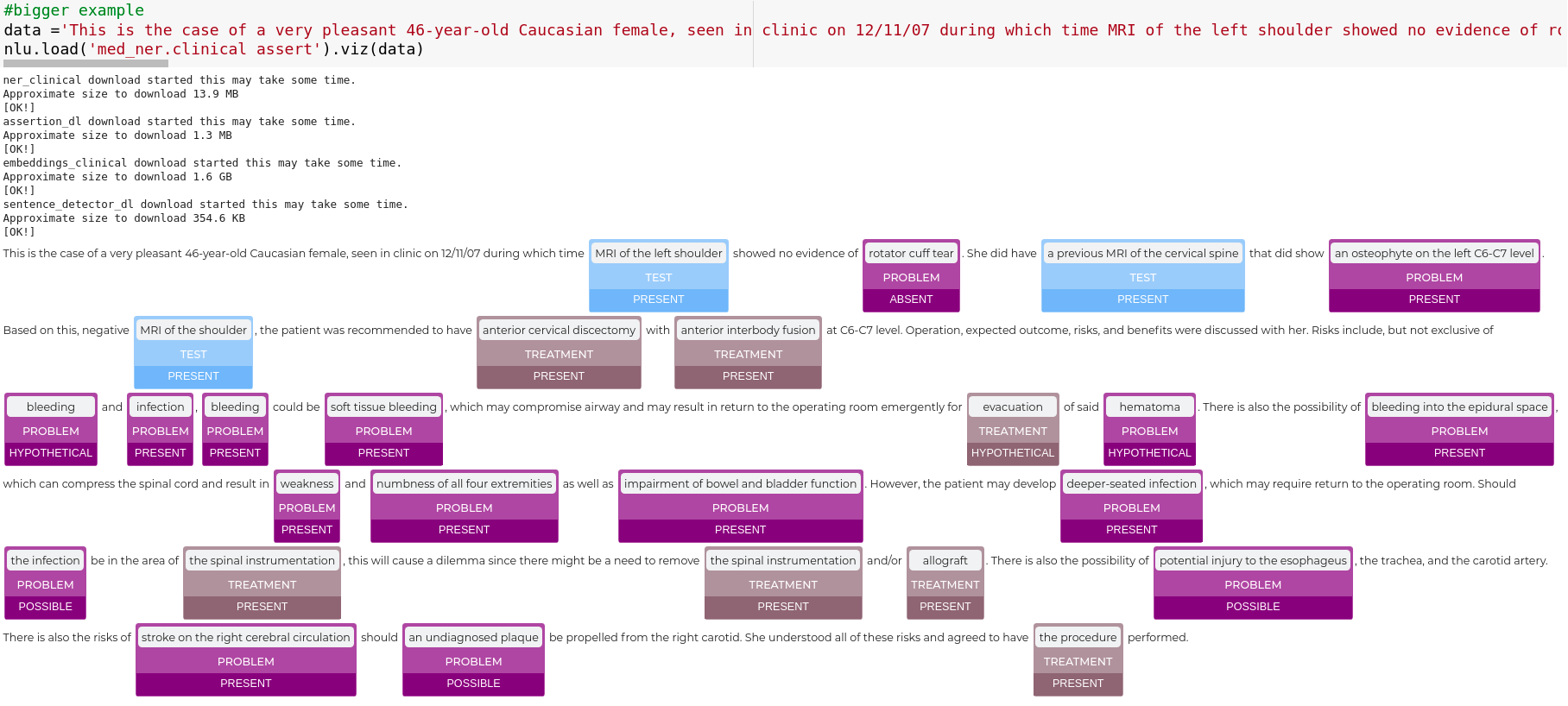
Relationship between entities visualization
Visualizes the extracted entities between relationship.
Applicable to any of the 20 + Relation Extractor models See here for an overview
nlu.load('med_ner.jsl.wip.clinical relation.temporal_events').viz('The patient developed cancer after a mercury poisoning in 1999 ')
# bigger example
data = 'This is the case of a very pleasant 46-year-old Caucasian female, seen in clinic on 12/11/07 during which time MRI of the left shoulder showed no evidence of rotator cuff tear. She did have a previous MRI of the cervical spine that did show an osteophyte on the left C6-C7 level. Based on this, negative MRI of the shoulder, the patient was recommended to have anterior cervical discectomy with anterior interbody fusion at C6-C7 level. Operation, expected outcome, risks, and benefits were discussed with her. Risks include, but not exclusive of bleeding and infection, bleeding could be soft tissue bleeding, which may compromise airway and may result in return to the operating room emergently for evacuation of said hematoma. There is also the possibility of bleeding into the epidural space, which can compress the spinal cord and result in weakness and numbness of all four extremities as well as impairment of bowel and bladder function. However, the patient may develop deeper-seated infection, which may require return to the operating room. Should the infection be in the area of the spinal instrumentation, this will cause a dilemma since there might be a need to remove the spinal instrumentation and/or allograft. There is also the possibility of potential injury to the esophageus, the trachea, and the carotid artery. There is also the risks of stroke on the right cerebral circulation should an undiagnosed plaque be propelled from the right carotid. She understood all of these risks and agreed to have the procedure performed'
pipe = nlu.load('med_ner.jsl.wip.clinical relation.clinical').viz(data)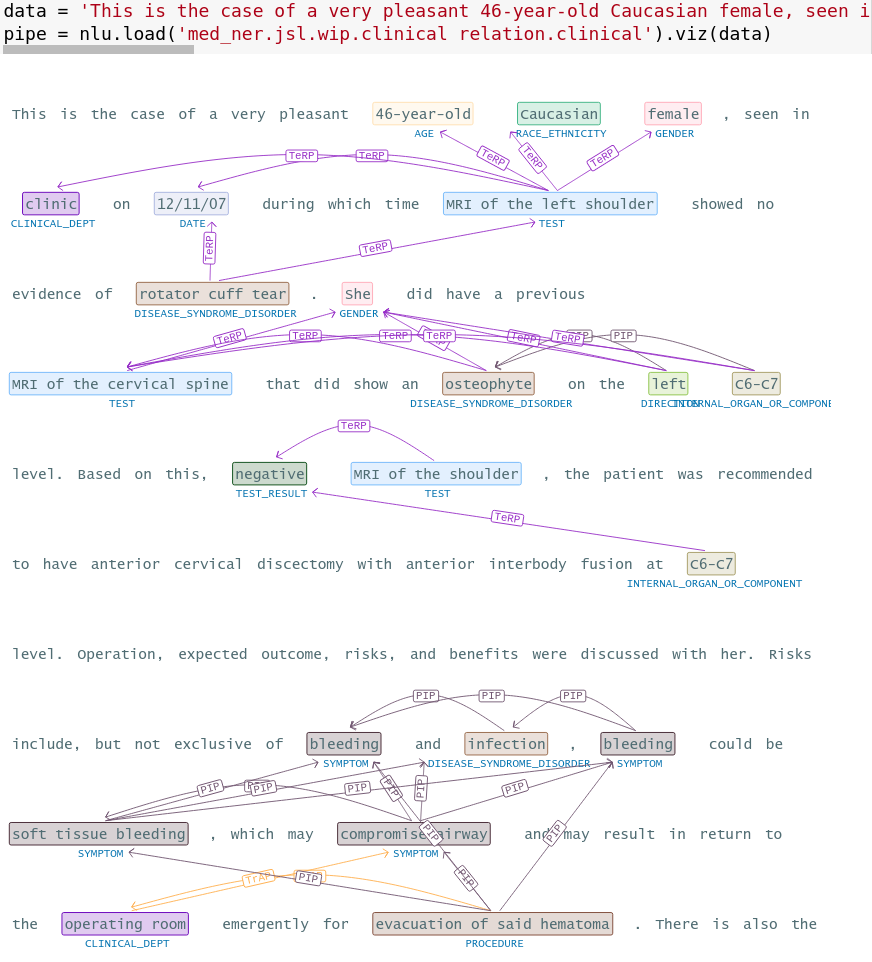
Entity Resolution visualization for chunks
Visualizes resolutions of entities
Applicable to any of the 100+ Resolver models See here for an overview
nlu.load('med_ner.jsl.wip.clinical resolve_chunk.rxnorm.in').viz("He took Prevacid 30 mg daily")
# bigger example
data = "This is an 82 - year-old male with a history of prior tobacco use , hypertension , chronic renal insufficiency , COPD , gastritis , and TIA who initially presented to Braintree with a non-ST elevation MI and Guaiac positive stools , transferred to St . Margaret\'s Center for Women & Infants for cardiac catheterization with PTCA to mid LAD lesion complicated by hypotension and bradycardia requiring Atropine , IV fluids and transient dopamine possibly secondary to vagal reaction , subsequently transferred to CCU for close monitoring , hemodynamically stable at the time of admission to the CCU ."
nlu.load('med_ner.jsl.wip.clinical resolve_chunk.rxnorm.in').viz(data)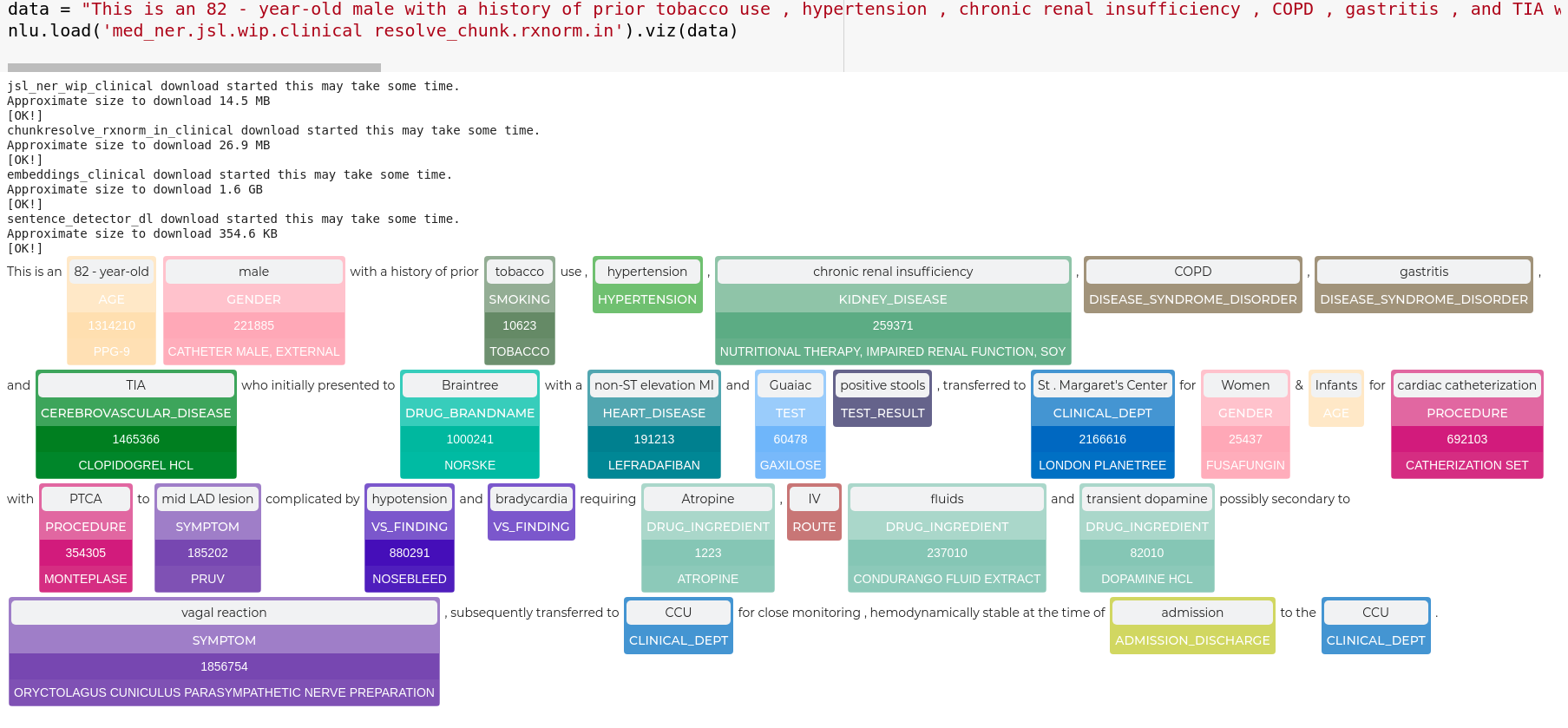
Entity Resolution visualization for sentences
Visualizes resolutions of entities in sentences
Applicable to any of the 100+ Resolver models See here for an overview
nlu.load('med_ner.jsl.wip.clinical resolve.icd10cm').viz('She was diagnosed with a respiratory congestion')
# bigger example
data = 'The patient is a 5-month-old infant who presented initially on Monday with a cold, cough, and runny nose for 2 days. Mom states she had no fever. Her appetite was good but she was spitting up a lot. She had no difficulty breathing and her cough was described as dry and hacky. At that time, physical exam sho...200+ State of the Art Medical Models for NER, Entity Resolution, Relation Extraction, Assertion, Spark 3 and Python 3.8 support - John Snow Labs NLU 3.0.0
200+ State of the Art Medical Models for NER, Entity Resolution, Relation Extraction, Assertion, Spark 3 and Python 3.8 support in NLU 3.0 Release and much more
We are incredibly excited to announce the release of NLU 3.0.0 which makes most of John Snow Labs medical healthcare model available in just 1 line of code in NLU.
These models are the most accurate in their domains and highly scalable in Spark clusters.
In addition, Spark 3.0.X and Spark 3.1.X is now supported, together with Python3.8
This is enabled by the amazing Spark NLP3.0.1 and Spark NLP for Healthcare 3.0.1 releases.
New Features
- Over 200 new models for the
healthcaredomain - 6 new classes of models, Assertion, Sentence/Chunk Resolvers, Relation Extractors, Medical NER models, De-Identificator Models
- Spark 3.0.X and 3.1.X support
- Python 3.8 Support
- New Output level
relation - 1 Line to install NLU just run
!wget https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/scripts/colab_setup.sh -O - | bash - Various new EMR and Databricks versions supported
- GPU Mode, more then 600% speedup by enabling GPU mode.
- Authorized mode for licensed features
New Documentation
New Notebooks
- Medical Named Entity Extraction (NER) notebook
- Relation extraction notebook
- Entity Resolution overview notebook
- Assertion overview notebook
- De-Identification overview notebook
- Graph NLU tutorial
AssertionDLModels
| Language | nlu.load() reference | Spark NLP Model reference |
|---|---|---|
| English | assert | assertion_dl |
| English | assert.biobert | assertion_dl_biobert |
| English | assert.healthcare | assertion_dl_healthcare |
| English | assert.large | assertion_dl_large |
New Word Embeddings
| Language | nlu.load() reference | Spark NLP Model reference |
|---|---|---|
| English | embed.glove.clinical | embeddings_clinical |
| English | embed.glove.biovec | embeddings_biovec |
| English | embed.glove.healthcare | embeddings_healthcare |
| English | embed.glove.healthcare_100d | embeddings_healthcare_100d |
| English | en.embed.glove.icdoem | embeddings_icdoem |
| English | en.embed.glove.icdoem_2ng | embeddings_icdoem_2ng |
Sentence Entity resolvers
RelationExtractionModel
| Language | nlu.load() reference | Spark NLP Model reference |
|---|---|---|
| English | relation.posology | posology_re |
| English | relation | redl_bodypart_direction_biobert |
| English | relation.bodypart.direction | redl_bodypart_direction_biobert |
| English | relation.bodypart.problem | [redl_bodypart_problem_biobert](https://nlp.johnsnowlabs.com/2021/02/04/re... |
1 Line to train a classifier for Reddit Sentiment, Amazone Phone reviews in 100+ languages, and much more with NLU 1.1.4!
NLU 1.1.4 Release Notes - Classify Reddit Sentiment, Amazone Phone reviews in 100+ languages, and much more with NLU 1.1.4!
We are very excited to announce NLU 1.1.4 has been released and comes with a lot of tutorials showcasing how you can train a multilingual text classifier on just one starting language which then will be able to classify labels correct for text in over 100+ languages.
This is possible by leveraging the language-agnostic BERT Sentence Embeddings(LABSE). In addition to that tutorials for English pure classifiers for stock market sentiment, sarcasm and negations have been added.
Finally, this release makes working in Spark environments easier, by providing a return_spark_df directly from NLU predictions.
New Features
- parameter on the
predict()method onnlu.load(). You can now callnlu.load(model).predict('Some data',return_spark_df=True)and will recieve a spark dataframe
New NLU Multi-Lingual training tutorials
These notebooks showcase how to leverage the powerful language-agnostic BERT Sentence Embeddings(LABSE) to train a language-agnostic classifier.
You can train on one start language(i.e. English dataset) and your model will be able to correctly predict the labels in every one of the 100+ languages of the LABSE embeddings.
- Multilingual Twitter Sentiment, binary classification (2class)
- Multilingual Stock Market Sentiment, binary classification (2class)
- Multilingual Reddit Comments Sentiment, binary classification (2class)
- Multilingual COVID19 Sentiment, binary classification (2class)
- Multilingual Apple Tweets Sentiment, binary classification (2class)
- Multilingual News classification, multi class classification (4class)
- Multilingual TripAdvisor Hotel Reviews, multi-class classification (3class)
- Multilingual Amazon Phone Reviews, multi-class classification (3class)
New NLU training tutorials (English)
These are simple training notebooks for binary classification for English
- Biological Texts Negation, binary classification (2class)
- News Headlines Sarcasm, binary classification (2class)
- COVID19 Sentiment, binary classification (2class)
- Natural Disasters Sentiment, binary classification (2class)
- Stock Market Sentiment, binary classification (2class)
Additional NLU ressources
Intent and Action Classification, analyze Chinese News and the Crypto market, train a classifier that understands 100+ languages, translate between 200 + languages, answer questions, summarize text and much more on NLU 1.1.3
NLU 1.1.3 Release Notes
We are very excited to announce that the latest NLU release comes with a new pretrained Intent Classifier and NER Action Extractor for text related to
music, restaurants, and movies trained on the SNIPS dataset. Make sure to check out the models hub and the easy 1-liners for more info!
In addition to that, new NER and Embedding models for Bengali are now available
Finally, there is a new NLU Webinar with 9 accompanying tutorial notebooks which teach you a lot of things and is segmented into the following parts :
- Part1: Easy 1 Liners
- Spell checking/Sentiment/POS/NER/ BERTtology embeddings
- Part2: Data analysis and NLP tasks on Crypto News Headline dataset
- Preprocessing and extracting Emotions, Keywords, Named Entities and visualize them
- Part3: NLU Multi-Lingual 1 Liners with Microsoft's Marian Models
- Translate between 200+ languages (and classify lang afterward)
- Part 4: Data analysis and NLP tasks on Chinese News Article Dataset
- Word Segmentation, Lemmatization, Extract Keywords, Named Entities and translate to english
- Part 5: Train a sentiment Classifier that understands 100+ Languages
- Train on a french sentiment dataset and predict the sentiment of 100+ languages with language-agnostic BERT Sentence Embedding
- Part 6: Question answering, Summarization, Squad and more with Google's T5
- T5 Question answering and 18 + other NLP tasks (SQUAD / GLUE / SUPER GLUE)
New Models
NLU 1.1.3 New Non-English Models
| Language | nlu.load() reference | Spark NLP Model reference | Type |
|---|---|---|---|
| Bengali | bn.ner.cc_300d | bengaliner_cc_300d | NerDLModel |
| Bengali | bn.embed | bengali_cc_300d | NerDLModel |
| Bengali | bn.embed.cc_300d | bengali_cc_300d | Word Embeddings Model (Alias) |
| Bengali | bn.embed.glove | bengali_cc_300d | Word Embeddings Model (Alias) |
NLU 1.1.3 New English Models
| Language | nlu.load() reference | Spark NLP Model reference | Type |
|---|---|---|---|
| English | en.classify.snips | nerdl_snips_100d | NerDLModel |
| English | en.ner.snips | classifierdl_use_snips | ClassifierDLModel |
New NLU Webinar
State-of-the-art Natural Language Processing for 200+ Languages with 1 Line of code
Talk Abstract
Learn to harness the power of 1,000+ production-grade & scalable NLP models for 200+ languages - all available with just 1 line of Python code by leveraging the open-source NLU library, which is powered by the widely popular Spark NLP.
John Snow Labs has delivered over 80 releases of Spark NLP to date, making it the most widely used NLP library in the enterprise and providing the AI community with state-of-the-art accuracy and scale for a variety of common NLP tasks. The most recent releases include pre-trained models for over 200 languages - including languages that do not use spaces for word segmentation algorithms like Chinese, Japanese, and Korean, and languages written from right to left like Arabic, Farsi, Urdu, and Hebrew. All software and models are free and open source under an Apache 2.0 license.
This webinar will show you how to leverage the multi-lingual capabilities of Spark NLP & NLU - including automated language detection for up to 375 languages, and the ability to perform translation, named entity recognition, stopword removal, lemmatization, and more in a variety of language families. We will create Python code in real-time and solve these problems in just 30 minutes. The notebooks will then be made freely available online.
You can watch the video here,
NLU 1.1.3 New Notebooks and tutorials
New Webinar Notebooks
- NLU basics, easy 1-liners (Spellchecking, sentiment, NER, POS, BERT
- Analyze Crypto News dataset with Keyword extraction, NER, Emotional distribution, and stemming
- Translate Crypto News dataset between 300 Languages with the Marian Model (German, French, Hebrew examples)
- Translate Crypto News dataset between 300 Languages with the Marian Model (Hindi, Russian, Chinese examples)
- Analyze Chinese News Headlines with Chinese Word Segmentation, Lemmatization, NER, and Keyword extraction
- Train a Sentiment Classifier that will understand 100+ languages on just a French Dataset with the powerful Language Agnostic Bert Embeddings
- Summarize text and Answer Questions with T5
- Solve any task in 1 line from SQUAD, GLUE and SUPER GLUE with T5
- Overview of models for various languages
New easy NLU 1-liners in NLU 1.1.3
Detect actions in general commands related to music, restaurant, movies.
nlu.load("en.classify.snips").predict("book a spot for nona gray myrtle and alison at a top-rated brasserie that is distant from wilson av on nov the 4th 2030 that serves ouzeri",output_level = "document")outputs :
| ner_confidence | entities | document | Entities_Classes |
|---|---|---|---|
| [1.0, 1.0, 0.9997000098228455, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.9990000128746033, 1.0, 1.0, 1.0, 0.9965000152587891, 0.9998999834060669, 0.9567000269889832, 1.0, 1.0, 1.0, 0.9980000257492065, 0.9991999864578247, 0.9988999962806702, 1.0, 1.0, 0.9998999834060669] | ['nona gray myrtle and alison', 'top-rated', 'brasserie', 'distant', 'wilson av', 'nov the 4th 2030', 'ouzeri'] | book a spot for nona gray myrtle and alison at a top-rated brasserie that is distant from wilson av on nov the 4th 2030 that serves ouzeri | ['party_size_description', 'sort', 'restaurant_type', 'spatial_relation', 'poi', 'timeRange', 'cuisine'] |
Named Entity Recognition (NER) Model in Bengali (bengaliner_cc_300d)
# Bengali for: 'Iajuddin Ahmed passed Matriculation from Munshiganj High School in 1947 and Intermediate from Munshiganj Horganga College in 1950.'
nlu.load("bn.ner.cc_300d").predict("১৯৪৮ সালে ইয়াজউদ্দিন আহম্মেদ মুন্সিগঞ্জ উচ্চ বিদ্যালয় থেকে মেট্রিক পাশ করেন এবং ১৯৫০ সালে মুন্সিগঞ্জ হরগঙ্গা কলেজ থেকে ইন্টারমেডিয়েট পাশ করেন",output_le...Hindi WordEmbeddings , Bengali Named Entity Recognition (NER), 30+ new models, analyze Crypto news with John Snow Labs NLU 1.1.2
NLU 1.1.2 Release Notes
We are very happy to announce NLU 1.1.2 has been released with the integration of 30+ models and pipelines Bengali Named Entity Recognition, Hindi Word Embeddings,
and state-of-the-art transformer based OntoNotes models and pipelines from the incredible Spark NLP 2.7.3 Release in addition to a few bugfixes.
In addition to that, there is a new NLU Webinar video showcasing in detail
how to use NLU to analyze a crypto news dataset to extract keywords unsupervised and predict sentimential/emotional distributions of the dataset and much more!
Python's NLU library: 1,000+ models, 200+ Languages, State of the Art Accuracy, 1 Line of code - NLU NYC/DC NLP Meetup Webinar
Using just 1 line of Python code by leveraging the NLU library, which is powered by the award-winning Spark NLP.
This webinar covers, using live coding in real-time,
how to deliver summarization, translation, unsupervised keyword extraction, emotion analysis,
question answering, spell checking, named entity recognition, document classification, and other common NLP tasks. T
his is all done with a single line of code, that works directly on Python strings or pandas data frames.
Since NLU is based on Spark NLP, no code changes are required to scale processing to multi-core or cluster environment - integrating natively with Ray, Dask, or Spark data frames.
The recent releases for Spark NLP and NLU include pre-trained models for over 200 languages and language detection for 375 languages.
This includes 20 languages families; non-Latin alphabets; languages that do not use spaces for word segmentation like
Chinese, Japanese, and Korean; and languages written from right to left like Arabic, Farsi, Urdu, and Hebrew.
We'll also cover some of the algorithms and models that are included. The code notebooks will be freely available online.
NLU 1.1.2 New Models and Pipelines
NLU 1.1.2 New Non-English Models
| Language | nlu.load() reference | Spark NLP Model reference | Type |
|---|---|---|---|
| Bengali | bn.ner | ner_jifs_glove_840B_300d | Word Embeddings Model (Alias) |
| Bengali | bn.ner.glove | ner_jifs_glove_840B_300d | Word Embeddings Model (Alias) |
| Hindi | hi.embed | hindi_cc_300d | NerDLModel |
| Bengali | bn.lemma | lemma | Lemmatizer |
| Japanese | ja.lemma | lemma | Lemmatizer |
| Bihari | bh.lemma | lemma | Lemma |
| Amharic | am.lemma | lemma | Lemma |
NLU 1.1.2 New English Models and Pipelines
New Tutorials and Notebooks
- NYC/DC NLP Meetup Webinar video analyze Crypto News, Unsupervised Keywords, Translate between 300 Languages, Question Answering, Summerization, POS, NER in 1 line of code in almost just 20 minutes
- NLU basics POS/NER/Sentiment Classification/BERTology Embeddings
- Explore Crypto Newsarticle dataset, unsupervised Keyword extraction, Stemming, Emotion/Sentiment distribution Analysis
- Translate between more than 300 Languages in 1 line of code with the Marian Models
- New NLU 1.1.2 Models Showcase Notebooks, Bengali NER, Hindi Embeddings, 30 new_models
NLU 1.1.2 Bug Fixes
- Fixed a bug that caused NER confidences not beeing extracted
- Fixed a bug that caused nlu.load('spell') to crash
- Fixed a bug that caused Uralic/Estonian/ET language models not to be loaded properly
New Easy NLU 1-liners in 1.1.2
[Named Entity Recognition for Bengali (GloVe 840B 300d)](https://nlp.johnsnowlabs.com/2021/01/27/ner_jifs_glove_840B_300d...
John Snow Labs NLU 1.1.1 : New multilingual models, Spark 2.3 support, new tutorials and more!
John Snow Labs NLU 1.1.1 : New multilingual models, Spark 2.3 support, new tutorials and more!
NLU 1.1.1 Release Notes
We are very excited to release NLU 1.1.1!
This release features 3 new tutorial notebooks for Open/Closed book question answering with Google's T5, Intent classification, and Aspect Based NER.
In Addition, NLU 1.1.0 comes with 25+ pre-trained models and pipelines in Amharic, Bengali, Bhojpuri, Japanese, and Korean languages from the amazing Spark2.7.2 release
Finally, NLU now supports running on Spark 2.3 clusters.
NLU 1.1.0 New Non-English Models
| Language | nlu.load() reference | Spark NLP Model reference | Type |
|---|---|---|---|
| Arabic | ar.ner | arabic_w2v_cc_300d | Named Entity Recognizer |
| Arabic | ar.embed.aner | aner_cc_300d | Word Embedding |
| Arabic | ar.embed.aner.300d | aner_cc_300d | Word Embedding (Alias) |
| Bengali | bn.stopwords | stopwords_bn | Stopwords Cleaner |
| Bengali | bn.pos | pos_msri | Part of Speech |
| Thai | th.segment_words | wordseg_best | Word Segmenter |
| Thai | th.pos | pos_lst20 | Part of Speech |
| Thai | th.sentiment | sentiment_jager_use | Sentiment Classifier |
| Thai | th.classify.sentiment | sentiment_jager_use | Sentiment Classifier (Alias) |
| Chinese | zh.pos.ud_gsd_trad | pos_ud_gsd_trad | Part of Speech |
| Chinese | zh.segment_words.gsd | wordseg_gsd_ud_trad | Word Segmenter |
| Bihari | bh.pos | pos_ud_bhtb | Part of Speech |
| Amharic | am.pos | pos_ud_att | Part of Speech |
NLU 1.1.1 New English Models and Pipelines
New Easy NLU 1-liner Examples :
Extract aspects and entities from airline questions (ATIS dataset)
nlu.load("en.ner.atis").predict("i want to fly from baltimore to dallas round trip")
output: ["baltimore"," dallas", "round trip"]Intent Classification for Airline Traffic Information System queries (ATIS dataset)
nlu.load("en.classify.questions.atis").predict("what is the price of flight from newyork to washington")
output: "atis_airfare" Recognize Entities OntoNotes - ELECTRA Large
nlu.load("en.ner.onto.large").predict("Johnson first entered politics when elected in 2001 as a member of Parliament. He then served eight years as the mayor of London.")
output: ["Johnson", "first", "2001", "eight years", "London"] Question classification of open-domain and fact-based questions Pipeline - TREC50
nlu.load("en.classify.trec50.pipe").predict("When did the construction of stone circles begin in the UK? ")
output: LOC_otherTraditional Chinese Word Segmentation
# 'However, this treatment also creates some problems' in Chinese
nlu.load("zh.segment_words.gsd").predict("然而,這樣的處理也衍生了一些問題。")
output: ["然而",",","這樣","的","處理","也","衍生","了","一些","問題","。"]Part of Speech for Traditional Chinese
# 'However, this treatment also creates some problems' in Chinese
nlu.load("zh.pos.ud_gsd_trad").predict("然而,這樣的處理也衍生了一些問題。")Output:
| Token | POS |
|---|---|
| 然而 | ADV |
| , | PUNCT |
| 這樣 | PRON |
| 的 | PART |
| 處理 | NOUN |
| 也 | ADV |
| 衍生 | VERB |
| 了 | PART |
| 一些 | ADJ |
| 問題 | NOUN |
| 。 | PUNCT |
Thai Word Segment Recognition
# 'Mona Lisa is a 16th-century oil painting created by Leonardo held at the Louvre in Paris' in Thai
nlu.loadnlu.load("th.segment_words").predict("Mona Lisa เป็นภาพวาดสีน้ำมันในศตวรรษที่ 16 ที่สร้างโดย Leonardo จัดขึ้นที่พิพิธภัณฑ์ลูฟร์ในปารีส")Output:
| token |
|---|
| M |
| o |
| n |
| a |
| Lisa |
| เป็น |
| ภาพ |
| ว |
| า |
| ด |
| สีน้ำ |
| มัน |
| ใน |
| ศตวรรษ |
| ที่ |
| 16 |
| ที่ |
| สร้าง |
| โ |
| ด |
| ย |
| L |
| e |
| o |
| n |
| a |
| r |
| d |
| o |
| จัด |
| ขึ้น |
| ที่ |
| พิพิธภัณฑ์ |
| ลูฟร์ |
| ใน |
| ปารีส |
Part of Speech for Bengali (POS)
# 'The...720+ new NLP models, 300+ supported languages, translation, summarization, question answering and more with T5 and Marian models! - John Snow Labs NLU 1.1.0
720+ new NLP models, 300+ supported languages, translation, summarization, question answering and more with T5 and Marian models! - John Snow Labs NLU 1.1.0
NLU 1.1.0 Release Notes
We are incredibly excited to release NLU 1.1.0!
This release integrates the 720+ new models from the latest Spark-NLP 2.7.0 + releases
You can now achieve state-of-the-art results with Sequence2Sequence transformers on problems like text summarization, question answering, translation between 192+ languages, and extract Named Entity in various Right to Left written languages like Arabic, Persian, Urdu, and languages that require segmentation like Koreas, Japanese, Chinese, and many more in 1 line of code!
These new features are possible because of the integration of the Google's T5 models and Microsoft's Marian models transformers
NLU 1.1.0 has over 720+ new pretrained models and pipelines while extending the support of multi-lingual models to 192+ languages such as Chinese, Japanese, Korean, Arabic, Persian, Urdu, and Hebrew.
NLU 1.1.0 New Features
- 720+ new models you can find an overview of all NLU models here and further documentation in the models hub
- NEW: Introducing MarianTransformer annotator for machine translation based on MarianNMT models. Marian is an efficient, free Neural Machine Translation framework mainly being developed by the Microsoft Translator team (646+ pretrained models & pipelines in 192+ languages)
- NEW: Introducing T5Transformer annotator for Text-To-Text Transfer Transformer (Google T5) models to achieve state-of-the-art results on multiple NLP tasks such as Translation, Summarization, Question Answering, Sentence Similarity, and so on
- NEW: Introducing brand new and refactored language detection and identification models. The new LanguageDetectorDL is faster, more accurate, and supports up to 375 languages
- NEW: Introducing WordSegmenter model for word segmentation of languages without any rule-based tokenization such as Chinese, Japanese, or Korean
- NEW: Introducing DocumentNormalizer component for cleaning content from HTML or XML documents, applying either data cleansing using an arbitrary number of custom regular expressions either data extraction following the different parameters
NLU 1.1.0 New Notebooks for new features
- Translate between 192+ languages with marian
- Try out the 18 Tasks like Summarization Question Answering and more on T5
- Tokenize, extract POS and NER in Chinese
- Tokenize, extract POS and NER in Korean
- Tokenize, extract POS and NER in Japanese
- Normalize documents
- Aspect based sentiment NER sentiment for restaurants
NLU 1.1.0 New Classifier Training Tutorials
Binary Classifier training Jupyter tutorials
- 2 class Finance News sentiment classifier training
- 2 class Reddit comment sentiment classifier training
- 2 class Apple Tweets sentiment classifier training
- 2 class IMDB Movie sentiment classifier training
- 2 class twitter classifier training
Multi Class text Classifier training Jupyter tutorials
- 5 class WineEnthusiast Wine review classifier training
- 3 class Amazon Phone review classifier training
- 5 class Amazon Musical Instruments review classifier training
- 5 class Tripadvisor Hotel review classifier training
- 5 class Phone review classifier training
NLU 1.1.0 New Medium Tutorials
- 1 line to Glove Word Embeddings with NLU with t-SNE plots
- 1 line to Xlnet Word Embeddings with NLU with t-SNE plots
- 1 line to AlBERT Word Embeddings with NLU with t-SNE plots
- 1 line to CovidBERT Word Embeddings with NLU with t-SNE plots
- 1 line to Electra Word Embeddings with NLU with t-SNE plots
- 1 line to BioBERT Word Embeddings with NLU with t-SNE plots
Translation
Translation example
You can translate between more than 192 Languages pairs with the Marian Models
You need to specify the language your data is in as start_language and the language you want to translate to as target_language.
The language references must be ISO language codes
nlu.load('<start_language>.translate.<target_language>')
Translate Turkish to English:
nlu.load('tr.translate_to.en')
Translate English to French:
nlu.load('en.translate_to.fr')
Translate French to Hebrew:
nlu.load('fr.translate_to.he')
Translate English to Chinese:
nlu.load('en.translate_to.zh)
Translate English to Korean:
nlu.load('en.translate_to.ko)
Translate English to Japanese:
nlu.load('en.translate_to.ja)
Translate English to Urdu:
nlu.load('en.translate_to.ur)
translate_pipe = nlu.load('en.translate_to.de')
df = translate_pipe.predict('Billy likes to go to the mall every sunday')
df| sentence | translation |
|---|---|
| Billy likes to go to the mall every sunday | Billy geht gerne jeden Sonntag ins Einkaufszentrum |
T5
Overview of every task available with T5
The T5 model is trained on various datasets for 17 different tasks which fall into 8 categories.
- Text summarization
- Question answering
- Translation
- Sentiment analysis
- Natural Language inference
- Coreference resolution
- Sentence Completion
- Word sense disambiguation
Every T5 Task with explanation:
| Task Name | Explanation |
|---|---|
| 1.CoLA | Classify if a sentence is grammatically correct |
| 2.RTE | Classify whether a statement can be deducted from a sentence |
| 3.MNLI | Classify for a hypothesis and premise whether they contradict or contradict each other or neither of both (3 class). |
| 4.MRPC | Classify whether a pair of... |
Trainable Multi Label Classifiers, predict Stackoverflow Tags and achieve State Of the Art Results results in 1 Line of with NLU 1.0.6
NLU 1.0.6 Release Notes
Trainable Multi-Label Classifiers, predict Stackoverflow Tags and much more in 1 Line of Python Code with NLU 1.0.6
We are glad to announce NLU 1.0.6 has been released!
NLU 1.0.6 comes with the Multi-Label classifier, it can learn to map strings to multiple labels.
The Multi-Label Classifier is using Bidirectional GRU and CNN's inside TensorFlow and supports up to 100 classes.
We provide examples on how to train a Multi-Label classifier on the E2E dataset and on Stack Overflow Question Tags.
NLU 1.0.6 New Features
- Multi-Label Classifier
- The Multi-Label Classifier learns a 1 to many mapping between text and labels. This means it can predict multiple labels at the same time for a given input string. This is very helpful for tasks similar to content tag prediction (HashTags/RedditTags/YoutubeTags/Toxic/E2e etc..)
- Support up to 100 classes
- Pre-trained Multi Label Classifiers are already avaiable as Toxic and E2E classifiers
Multi Label Classifier
- Train Multi Label Classifier on E2E dataset
- Train Multi-Label Classifier on Stack Overflow Question Tags dataset
This model can predict multiple labels for one sentence.
To train the Multi-Label text classifier model, you must pass a dataframe with atextcolumn and aycolumn for the label.
Theylabel must be a string column where each label is separated with a separator.
By default,,is assumed as line separator.
If your dataset is using a different label separator, you must configure thelabel_separatorparameter while calling thefit()method.
By default, Universal Sentence Encoder Embeddings (USE) are used as sentence embeddings for training.
fitted_pipe = nlu.load('train.multi_classifier').fit(train_df)
preds = fitted_pipe.predict(train_df)If you add a nlu sentence embeddings reference, before the train reference, NLU will use that Sentence embeddings instead of the default USE.
#Train on BERT sentence emebddings
fitted_pipe = nlu.load('embed_sentence.bert train.multi_classifier').fit(train_df)
preds = fitted_pipe.predict(train_df)Configure a custom line seperator
#Use ; as label seperator
fitted_pipe = nlu.load('embed_sentence.electra train.multi_classifier').fit(train_df, label_seperator=';')
preds = fitted_pipe.predict(train_df)NLU 1.0.6 Enhancements
- Improved outputs for Toxic and E2E Classifier.
- by default, all predicted classes and their confidences that are above the threshold will be returned inside of a list in the Pandas dataframe
- by configuring meta=True, the confidences for all classes will be returned.
NLU 1.0.6 New Notebooks and Tutorials
- Train Multi Label Classifier on E2E dataset
- Train Multi-Label Classifier on Stack Overflow Question Tags dataset
NLU 1.0.6 Bug-fixes
- Fixed a bug that caused
en.ner.dl.bertto be inaccessible - Fixed a bug that caused
pt.ner.largeto be inaccessible - Fixed a bug that caused USE embeddings not being properly configured to document level output when using multiple embeddings at the same time
Trainable Part of Speech Tagger (POS), Sentiment Classifier with BERT/USE/ELECTRA sentence embeddings in 1 Line of code! Latest NLU Release 1.0.5
NLU 1.0.5 Release Notes
We are glad to announce NLU 1.0.5 has been released!
This release comes with a trainable Sentiment classifier and a Trainable Part of Speech (POS) models!
These Neural Network Architectures achieve the state of the art (SOTA) on most binary Sentiment analysis and Part of Speech Tagging tasks!
You can train the Sentiment Model on any of the 100+ Sentence Embeddings which include BERT, ELECTRA, USE, Multi Lingual BERT Sentence Embeddings and many more!
Leverage this and achieve the state of the art in any of your datasets, all of this in just 1 line of Python code
NLU 1.0.5 New Features
- Trainable Sentiment DL classifier
- Trainable POS
NLU 1.0.5 New Notebooks and Tutorials
Sentiment Classifier Training
Sentiment Classification Training Demo
To train the Binary Sentiment classifier model, you must pass a dataframe with a 'text' column and a 'y' column for the label.
By default Universal Sentence Encoder Embeddings (USE) are used as sentence embeddings.
fitted_pipe = nlu.load('train.sentiment').fit(train_df)
preds = fitted_pipe.predict(train_df)If you add a nlu sentence embeddings reference, before the train reference, NLU will use that Sentence embeddings instead of the default USE.
#Train NER on BERT sentence embeddings
fitted_pipe = nlu.load('embed_sentence.bert train.classifier').fit(train_df)
preds = fitted_pipe.predict(train_df)#Train NER on ELECTRA sentence embeddings
fitted_pipe = nlu.load('embed_sentence.electra train.classifier').fit(train_df)
preds = fitted_pipe.predict(train_df)Part Of Speech Tagger Training
Your dataset must be in the form of universal dependencies Universal Dependencies.
You must configure the dataset_path in the fit() method to point to the universal dependencies you wish to train on.
You can configure the delimiter via the label_seperator parameter
[POS training demo]](https://colab.research.google.com/drive/1CZqHQmrxkDf7y3rQHVjO-97tCnpUXu_3?usp=sharing)
fitted_pipe = nlu.load('train.pos').fit(dataset_path=train_path, label_seperator=',')
preds = fitted_pipe.predict(train_df)NLU 1.0.5 Installation changes
Starting from version 1.0.5 NLU will not automatically install pyspark for users anymore.
This enables easier customizing the Pyspark version which makes it easier to use in various cluster environments.
To install NLU from now on, please run
pip install nlu pyspark==2.4.7 or install any pyspark>=2.4.0 with pyspark<3
NLU 1.0.5 Improvements
- Improved Databricks path handling for loading and storing models.
John Snow Labs NLU 1.0.4 : Trainable Named Entity Recognizer (NER) , achieve SOTA in 1 line of code and easy scaling to 100's of Spark nodes
1.0.4 Release Notes
We are glad to announce NLU 1.0.4 releases the State of the Art breaking Neural Network architecture for NER, Char CNNs - BiLSTM - CRF!
With it you can state-of-the-art in most NER datasets, of course in just 1 line of Python code. It is using Spark NLP's very popular NER DL under the hood.
#fit and predict in 1 line!
nlu.load('train.ner').fit(dataset).predict(dataset)
#fit and predict in 1 line with BERT!
nlu.load('bert train.ner').fit(dataset).predict(dataset)
#fit and predict in 1 line with ALBERT!
nlu.load('albert train.ner').fit(dataset).predict(dataset)
#fit and predict in 1 line with ELMO!
nlu.load('elmo train.ner').fit(dataset).predict(dataset)Any NLU pipeline stored can now be loaded as pyspark ML pipeline
# Ready for big Data with Spark distributed computing
import pyspark
nlu_pipe.save(path)
pyspark_pipe = pyspark.ml.PipelineModel.load(stored_model_path)
pyspark_pipe.transform(spark_df)NLU 1.0.4 New Features
- Trainable Named Entity Recognizer
- NLU pipeline loadable as Spark pipelines
NLU 1.0.4 New Notebooks,Tutorials and Docs
- NER training demo
- Multi Class Text Classifier Training Demo updated to showcase the usage of different Embeddings
- New Documentation Page on how to train Models with NLU
- Databricks Notebook showcasing Scaling with NLU
NLU 1.0.4 Bug Fixes
- Fixed a bug that NER token confidences do not appear. They now appear when nlu.load('ner').predict(df, meta=True) is called.
- Fixed a bug that caused some Spark NLP models to not be loaded properly in offline mode