Our method is directly applicable to all SD-v1 and v2 versions, removing specific residual and attention blocks from the U-Net architecture. For further details, refer to our ArXiv paper. Below, SD-v1.4 is shown as an example.
- 1.04B-param SDM-v1.4 (0.86B-param U-Net): the original source model.
- 0.76B-param BK-SDM-Base (0.58B-param U-Net): obtained with ① fewer blocks in outer stages.
- 0.66B-param BK-SDM-Small (0.49B-param U-Net): obtained with ① and ② mid-stage removal.
- 0.50B-param BK-SDM-Tiny (0.33B-param U-Net): obtained with ①, ②, and ③ further inner-stage removal.
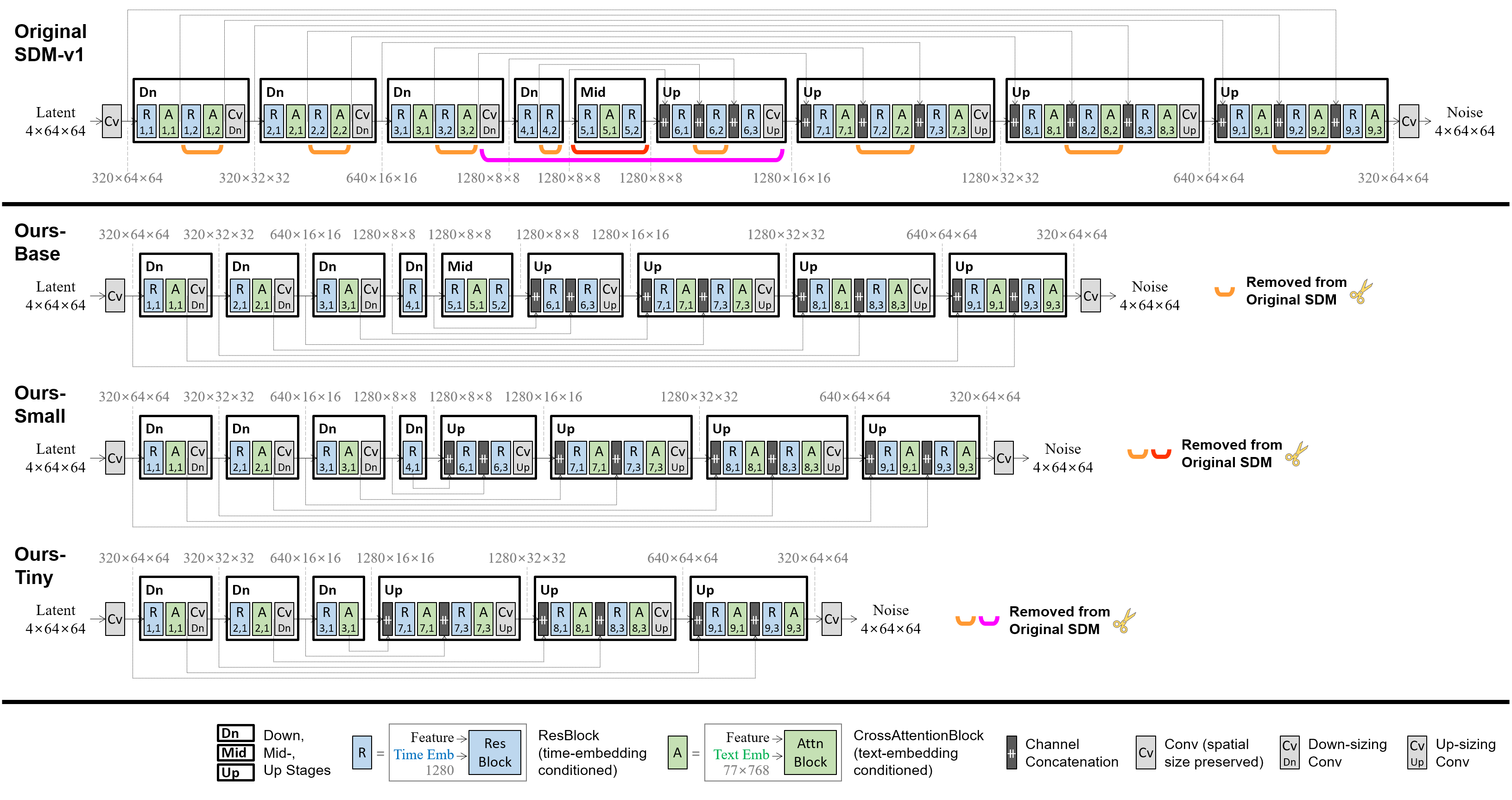
The compact U-Net was trained to mimic the behavior of the original U-Net. We leveraged feature-level and output-level distillation, along with the denoising task loss.

- Training Data
- BK-SDM: 212,776 image-text pairs (i.e., 0.22M pairs) from LAION-Aesthetics V2 6.5+.
- BK-SDM-2M: 2,256,472 image-text pairs (i.e., 2.3M pairs) from LAION-Aesthetics V2 6.25+.
- Hardware: A single NVIDIA A100 80GB GPU
- Gradient Accumulations: 4
- Batch: 256 (=4×64)
- Optimizer: AdamW
- Learning Rate: a constant learning rate of 5e-5 for 50K-iteration pretraining
The following table shows the results on 30K samples from the MS-COCO validation split. After generating 512×512 images with the PNDM scheduler and 25 denoising steps, we downsampled them to 256×256 for evaluating generation scores.
| Model | FID↓ | IS↑ | CLIP Score↑ (ViT-g/14) |
# Params, U-Net |
# Params, Whole SDM |
|---|---|---|---|---|---|
| Stable Diffusion v2.1-base | 13.93 | 35.93 | 0.3075 | 0.87B | 1.26B |
| BK-SDM-v2-Base (Ours) | 15.85 | 31.70 | 0.2868 | 0.59B | 0.98B |
| BK-SDM-v2-Small (Ours) | 16.61 | 31.73 | 0.2901 | 0.49B | 0.88B |
| BK-SDM-v2-Tiny (Ours) | 15.68 | 31.64 | 0.2897 | 0.33B | 0.72B |
| Model | FID↓ | IS↑ | CLIP Score↑ (ViT-g/14) |
# Params, U-Net |
# Params, Whole SDM |
|---|---|---|---|---|---|
| Stable Diffusion v1.4 | 13.05 | 36.76 | 0.2958 | 0.86B | 1.04B |
| BK-SDM-Base (Ours) | 15.76 | 33.79 | 0.2878 | 0.58B | 0.76B |
| BK-SDM-Base-2M (Ours) | 14.81 | 34.17 | 0.2883 | 0.58B | 0.76B |
| BK-SDM-Small (Ours) | 16.98 | 31.68 | 0.2677 | 0.49B | 0.66B |
| BK-SDM-Small-2M (Ours) | 17.05 | 33.10 | 0.2734 | 0.49B | 0.66B |
| BK-SDM-Tiny (Ours) | 17.12 | 30.09 | 0.2653 | 0.33B | 0.50B |
| BK-SDM-Tiny-2M (Ours) | 17.53 | 31.32 | 0.2690 | 0.33B | 0.50B |
The following figure depicts synthesized images with some MS-COCO captions.

Increasing the number of training pairs improves the IS and CLIP scores over training progress. The MS-COCO 256×256 30K benchmark was used for evaluation.

Furthermore, with the growth in data volume, visual results become more favorable (e.g., better image-text alignment and clear distinction among objects).


To show the applicability of our lightweight SD backbones, we use DreamBooth finetuning for personalized generation.
- Each subject is marked as "a [identifier] [class noun]" (e.g., "a [V] dog").
- Our BK-SDMs can synthesize the input subjects in different backgrounds while preserving their appearance.
