![]()
![]()
![]()
Apache Amoro (incubating) is a Lakehouse management system built on open data lake formats. Working with compute engines including Flink, Spark, and Trino, Amoro brings pluggable and self-managed features for Lakehouse to provide out-of-the-box data warehouse experience, and helps data platforms or products easily build infra-decoupled, stream-and-batch-fused and lake-native architecture.
Learn more about Amoro at https://amoro.apache.org/, contact the developers and community on the mailing list if you need any help.
Here is the architecture diagram of Amoro:
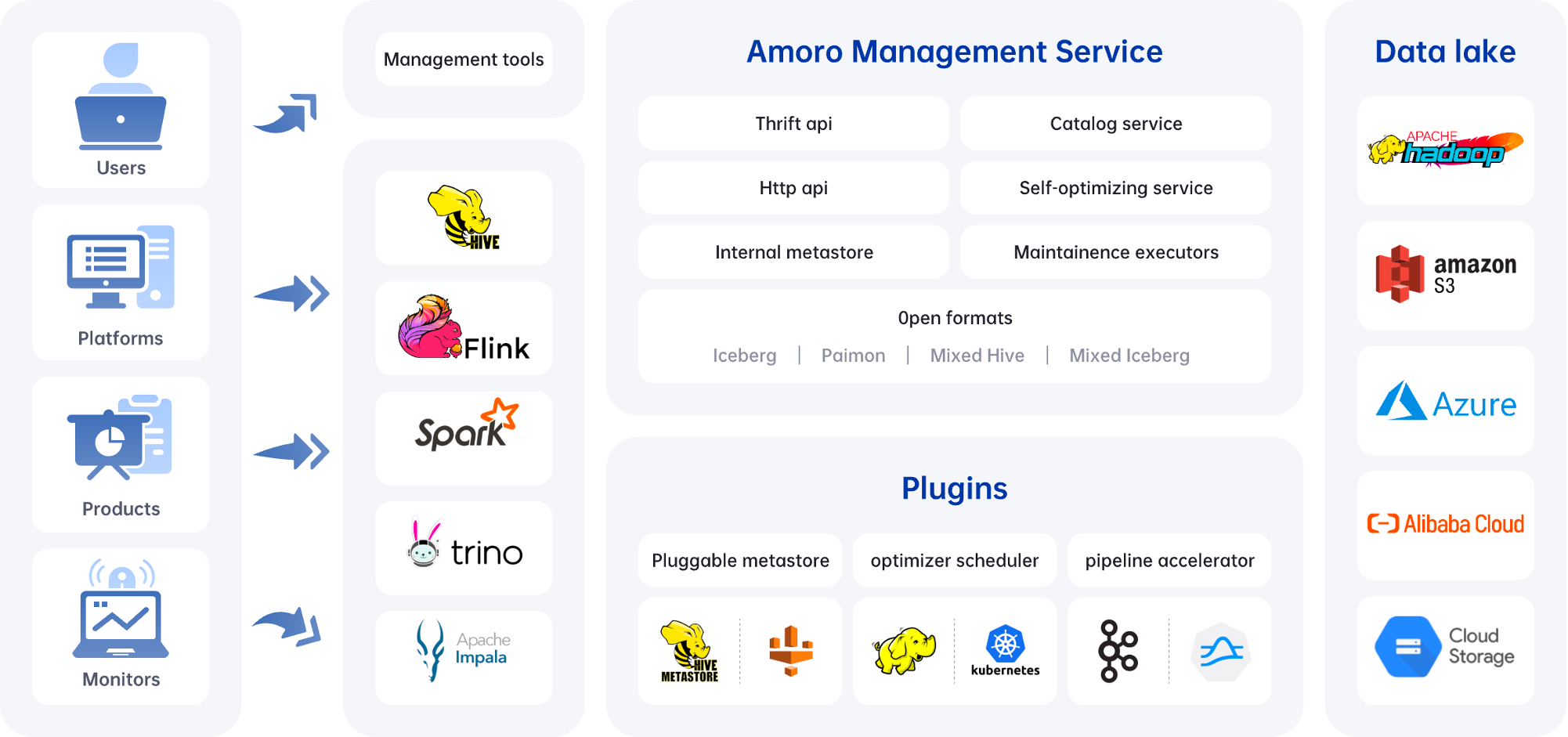
- AMS: Amoro Management Service provides Lakehouse management features, like self-optimizing, data expiration, etc. It also provides a unified catalog service for all compute engines, which can also be combined with existing metadata services.
- Plugins: Amoro provides a wide selection of external plugins to meet different scenarios.
- Optimizers: The self-optimizing execution engine plugin asynchronously performs merging, sorting, deduplication, layout optimization, and other operations on all type table format tables.
- Terminal: SQL command-line tools, provide various implementations like local Spark and Kyuubi.
- LogStore: Provide millisecond to second level SLAs for real-time data processing based on message queues like Kafka and Pulsar.
Amoro can manage tables of different table formats, similar to how MySQL/ClickHouse can choose different storage engines. Amoro meets diverse user needs by using different table formats. Currently, Amoro supports four table formats:
- Iceberg format: Users can directly entrust their Iceberg tables to Amoro for maintenance, so that users can not only use all the functions of Iceberg tables, but also enjoy the performance and stability improvements brought by Amoro.
- Mixed-Iceberg format: Amoro provides a set of more optimized formats for streaming update scenarios on top of the Iceberg format. If users have high performance requirements for streaming updates or have demands for CDC incremental data reading functions, they can choose to use the Mixed-Iceberg format.
- Mixed-Hive format: Many users do not want to affect the business originally built on Hive while using data lakes. Therefore, Amoro provides the Mixed-Hive format, which can upgrade Hive tables to Mixed-Hive format only through metadata migration, and the original Hive tables can still be used normally. This ensures business stability and benefits from the advantages of data lake computing.
- Paimon format: Amoro supports displaying metadata information in the Paimon format, including Schema, Options, Files, Snapshots, DDLs, and Compaction information.
Iceberg format tables use the engine integration method provided by the Iceberg community. For details, please refer to: Iceberg Docs.
Amoro support multiple processing engines for Mixed format as below:
| Processing Engine | Version | Batch Read | Batch Write | Batch Overwrite | Streaming Read | Streaming Write | Create Table | Alter Table |
|---|---|---|---|---|---|---|---|---|
| Flink | 1.15.x, 1.16.x, 1.17.x | ✔ | ✔ | ✖ | ✔ | ✔ | ✔ | ✖ |
| Spark | 3.1, 3.2, 3.3 | ✔ | ✔ | ✔ | ✖ | ✖ | ✔ | ✔ |
| Hive | 2.x, 3.x | ✔ | ✖ | ✔ | ✖ | ✖ | ✖ | ✔ |
| Trino | 406 | ✔ | ✖ | ✔ | ✖ | ✖ | ✖ | ✔ |
- Self-optimizing - Continuously optimizing tables, including compacting small files, change files, regularly delete expired files to keep high query performance and reducing storage costs.
- Multiple Formats - Support different table formats such as Iceberg, Mixed-Iceberg and Mixed-Hive to meet different scenario requirements and provide them with unified management capabilities.
- Catalog Service - Provide a unified catalog service for all compute engines, which can also used with existing metadata store service such as Hive Metastore and AWS Glue.
- Rich Plugins - Provide various plugins to integrate with other systems, like continuously optimizing with Flink and data analysis with Spark and Kyuubi.
- Management Tools - Provide a variety of management tools, including WEB UI and standard SQL command line, to help you get started faster and integrate with other systems more easily.
- Infrastructure Independent - Can be easily deployed and used in private environments, cloud environments, hybrid cloud environments, and multi-cloud environments.
Amoro contains modules as below:
amoro-commoncontains core abstractions and common implementation for other modulesamoro-amsis amoro management service moduleamoro-webis the dashboard frontend for amsamoro-optimizerprovides default optimizer implementationamoro-format-icebergcontains integration of Apache Iceberg formatamoro-format-hudicontains integration of Apache Hudi formatamoro-format-paimoncontains integration of Apache Paimon formatamoro-format-mixedprovides Mixed format implementationamoro-mixed-hiveintegrates with Apache Hive and implements Mixed Hive formatamoro-mixed-flinkprovides Flink connectors for Mixed format tables (use amoro-flink-runtime for a shaded version)amoro-mixed-sparkprovides Spark connectors for Mixed format tables (use amoro-spark-runtime for a shaded version)amoro-mixed-trinoprovides Trino connectors for Mixed format tables
Amoro is built using Maven with JDK 8 and JDK 17(only for amoro-format-mixed/amoro-mixed-trino module).
- Build all modules without
amoro-mixed-trino:mvn clean package - Build and skip tests:
mvn clean package -DskipTests - Build and skip dashboard:
mvn clean package -Pskip-dashboard-build - Build and disable disk storage, RocksDB will NOT be introduced to avoid memory overflow:
mvn clean package -DskipTests -Pno-extented-disk-storage - Build and enable aliyun-oss-sdk:
mvn clean package -DskipTests -Paliyun-oss-sdk - Build with hadoop 2.x(the default is 3.x) dependencies:
mvn clean package -DskipTests -Phadoop2 - Specify Flink version for Flink optimizer(the default is 1.20.0):
mvn clean package -DskipTests -Dflink-optimizer.flink-version=1.20.0- If the version of Flink is below 1.15.0, you also need to add the
-Pflink-optimizer-pre-1.15parameter:mvn clean package -DskipTests -Pflink-optimizer-pre-1.15 -Dflink-optimizer.flink-version=1.14.6
- If the version of Flink is below 1.15.0, you also need to add the
- Specify Spark version for Spark optimizer(the default is 3.3.3):
mvn clean package -DskipTests -Dspark-optimizer.spark-version=3.3.3 - Build
amoro-mixed-trinomodule under JDK 17:mvn clean package -DskipTests -Pformat-mixed-format-trino,build-mixed-format-trino -pl 'amoro-format-mixed/amoro-mixed-trino' -am. - Build all modules:
mvn clean package -DskipTests -Ptoolchain,build-mixed-format-trino, besides you need configtoolchains.xmlin${user.home}/.m2/dir with content below. - Build a distribution package with all formats integrated:
mvn clean package -Psupport-all-formats- Build a distribution package with Apache Paimon format:
mvn clean package -Psupport-paimon-format - Build a distribution package with Apache Hudi format:
mvn clean package -Psupport-hudi-format
- Build a distribution package with Apache Paimon format:
<?xml version="1.0" encoding="UTF-8"?>
<toolchains>
<toolchain>
<type>jdk</type>
<provides>
<version>17</version>
<vendor>sun</vendor>
</provides>
<configuration>
<jdkHome>${YourJDK17Home}</jdkHome>
</configuration>
</toolchain>
</toolchains>
Visit https://amoro.apache.org/quick-demo/ to quickly explore what amoro can do.
If you are interested in Lakehouse, Data Lake Format, welcome to join our community, we welcome any organizations, teams and individuals to grow together, and sincerely hope to help users better use Data Lake Format through open source.
Join the Amoro WeChat Group: Add " kllnn999 " as a friend on WeChat and specify "Amoro lover".
This project exists thanks to all the people who contribute.
Made with contrib.rocks.