+
+
+
+
+
+
+
+Manpage for sbank Commands
+sbank [options]
+DESCRIPTION
+HPC Accounting System Command Line Interface
+
+"detail" meta command displays information in a long format with history updates, where appropriate.
+
+"list" meta command displays information in a table format, but no history updates are displayed.
+IMPORTANT NOTES
+ 1. All dates entered shall be interpreted as UTC
+ 2. non-admin users will only be able to see their content (jobs, charges, etc.)
+ 3. project admin users will be able to see all of the content for their projects
+ 4. staff admin users will be able to see all the content
+ 5. --help and -h are the help options.
+
+- detail [options]
+- list [options] (DEFAULT)
+DETAIL COMMANDS
+ * allocations [-a|-e|-f|-j|-n|-p|-r|-t|-u|-w|-E|-H|-I|-O|-S|-T|...] [ ... ] (DEFAULT)
+ * jobs [-a|-e|-f|-j|-n|-p|-r|-t|-u|-w|-E|-H|-S|-T|...] [ ... ]
+ * projects [-a|-f|-n|-p|-r|-u|-w|-E|-H|-I|-S|...] [ ... ]
+ * transactions [-a|-e|-f|-j|-n|-p|-r|-t|-u|-w|-E|-H|-S|-T|...] [ ... ]
+ * users [-a|-f|-n|-p|-r|-u|-w|-E|-H|-S|...] [ ... ]
+LIST COMMANDS
+ * allocations [-a|-c|-e|-f|-j|-n|-p|-r|-t|-u|-w|-E|-H|-I|-O|-S|-T|...] (DEFAULT)
+ * jobs [-a|-e|-f|-j|-n|-p|-r|-t|-u|-w|-E|-H|-S|-T|...] projects [-a|-f|-n|-p|-r|-u|-w|-E|-H|-I|-S|...]
+ * transactions [-a|-c|-e|-f|-j|-n|-p|-r|-t|-u|-w|-E|-H|-S|-T|...]
+ * users [-a|-f|-n|-p|-r|-u|-w|-E|-H|-S|...]
+OPTIONS
+-a --allocation
+enter allocation id
+
+enter comment for new or edit commands, display comment for list commands
+-e --event-id
+enter event db id; event db id is an internal id created by the charging system
+-f --field
+enter [:], width is optional; enter -f? or -f "?" for available fields, + to add fields
+-h --help
+command line help
+-j --jobid
+enter jobid; jobid is created by the scheduler and is not unique
+-n --num-field
+enter number of fields to display
+-p --project
+enter name or id, DO NOT MIX, enter 'all' to get all, wild cards '*' is allowed, but only on names
+-r --resource
+enter name or id, DO NOT MIX, enter 'all' to get all, wild cards '*' is allowed, but only on names
+-s --suballocation
+enter suballocation id
+-t --transaction
+enter transaction id
+-u --user
+enter name or id, DO NOT MIX, enter 'all' to get all, wild cards '*' is allowed, but only on names
+-w --field-width
+enter the field width as follows: :, enter -w? or -w "?" for available fields
+-E --end
+enter end datetime filter
+-H --human-readable
+abbreviate numbers and use unit suffixes: K (thousands), M (millions), G (billions), T (trillions) ...
+-I --get-inactive
+include inactive allocations
+-O --get-only-inactive
+get only inactive allocations
+-S --start
+enter start datetime filter
+-T --Type
+enter type of transaction
+--all-charges
+for list allocations | projects | users, only show info with charges
+--at
+enter transaction-created datetime filter
+--award-category
+enter allocation award category
+--award-type-name
+enter allocation award-type name
+--created
+enter created datetime filter
+--debug
+enter debug level
+--get-deleted
+get deleted objects
+--get-not-charged
+get jobs that have not been charged
+--get-only-deleted
+get only deleted objects
+--history-date-range
+enter history datetime filter
+--home-dir
+enter the directory to store the pbs meta file
+--ignore-pbs-files
+all new pbs files will be ignored and marked as processed
+--last-updated
+enter last updated datetime filter
+--no-commas
+remove commas from comma-separated thousands
+
+do not display header
+--no-history
+do not display history information
+--no-rows
+do not display rows
+--no-sys-msg
+do not display system message
+--no-totals
+do not display totals
+--queued
+enter queued datetime filter
+MORE OPTION EXPLANATIONS
+For -a, -e, -f, -w, -j, -p, -r, -t, -u, -T, --award-categories, --award_type_names, --cbank_refs options:
+These options can be entered multiple times for different values or entered once for multiple values.
+Examples:
+
+-
+
+sbank-list-allocation -u "pershey rojas allcock" or > sbank-list-allocation -u pershey -u rojas -u allcock
+
+
+-
+
+sbank-list-allocation -f "id p avail" or > sbank-list-allocation -f id -f p -f avail For -u, -p and -r the use of wild card "*" is allowed, but only on names, not ids:
+
+
+
+Examples:
+
+- The following command will find allocations for users whose names start with "pers" and also users rojas and allcock. > sbank-list-allocation -u "pers* rojas allcock"
+- The following command will find allocations for projects that contain "ratio" in the name. > sbank-list-allocation -p ratio
+- The following command will find allocations for projects that end with "tion" in the name. > sbank-list-allocation -p *tion
+- The following command will find allocations for projects that start with "ab" and end with "ng" in the name. > sbank-list-allocation -p ab*ng
+
+For -f option:
+This option is the display field option.
+To get the available fields enter -f? or -f "?". Default fields columns will be displayed if no field option is specified.
+To replace the current fields to display, enter:
+
> sbank-list-allocations ... -f "FIELD[:WIDTH]...FIELD[:WIDTH]" or > sbank-list-allocations ... -f FIELD[:WIDTH] ... -f FIELD[:WIDTH]
+
If you wish to add fields to the default fields, enter one + symbol anywhere in the quoted string:
+
> sbank-list-allocations ... -f "+ FIELD[:WIDTH]...FIELD[:WIDTH]", only one + symbol is needed.
+
The fields will be displayed in table format and in the order entered in the command line. You can specify the field width, where WIDTH can be positive or negative value. Left alignment use -, right alignment use + or nothing.
+For -w option:
+FIELD:WIDTH, if the field is displayed it will change the width for the specified field.
+NOTE: This will not add the field as in -f option, only change the width. To get available fields you can also use -w? or -w "?" as in -f option.
+For -S, -E, --created, --queued, --last-updated, --history-date-range options:
+These are the date filter options. All dates are treated as UTC.
+You can use any reasonable date string that resembles a date Ambiguous dates will be parsed with the following parsing precedence: **YEAR then MONTH then DAY **
+For example, 10-11-12 or 101112 will be the following date: Oct. 11, 2012 Not: Nov. 12, 2010 or Nov. 10, 2012
+Or you can specify a single date as follows:
+
"[OPER]UTC_DATE" You can specify a date range as follows:
+"[OPER1]UTC_DATE1...[OPER2]UTC_DATE2" Where OPER can be one of the following operators: "==", ">=", "<=", ">", "<" or "eq", "ge", "le", "gt", "lt"
+
Note: The following defaults for OPER, OPER1, OPER2 for the following options:
+
Options OPER OPER1 OPER2 ------------------------- ---- ----- ----- -E, < >= < -S, >= >= < --at >= >= < --created >= >= < --eligible >= >= < --last-updated >= >= < --queued >= >= <
+
You can also use the following key letters "n", "t", "d", "w", "y" as follows:
+
KEY SYNTAX DEFINITIONS ---------- ----------- n[ow] now, where "now" is current-date current-time UTC t[oday] today, where "today" is current-date 00:00:00 UTC [+/-]d specified "number" of +/- days from "today" in UTC [+/-]w specified "number" of +/- weeks from "today" in UTC [+/-]y specified "number" of +/- years from "today" in UTC
+
For -T option:
+Transaction type option. The following are the valid transaction types and their explanation: CHARGE filter on job charges PULLBACK filter on allocation pullbacks DEPOSIT filter on allocation deposits REFUND filter on job refunds VOID filter on void transactions
+INVOCATION
+sbank sbank sbank sbank-detail sbank detail sbank d sbank-detail-allocations sbank detail allocations sbank d a sbank-detail-jobs sbank detail jobs sbank d j sbank-detail-projects sbank detail project sbank d p sbank-detail-transactions sbank detail transactions sbank d t sbank-detail-users sbank detail users sbank d u sbank-list sbank list sbank l sbank-list-allocations sbank list allocations sbank l a sbank-list-jobs sbank list jobs sbank l j sbank-list-projects sbank list projects sbank l p sbank-list-transactions sbank list transactions sbank l t sbank-list-users sbank list users sbank l u
+ENVIRONMENT VARIABLES
+Command line default options: Define the following environment variables as you would in the command line. Once the environment variable is defined, it will be used as the default options and arguments for the specific command. Command line options will take precedence.
+sbank_DETAIL_ALLOCATIONS_ARGS
+Default arguments and options for sbank-detail-allocations.
+sbank_DETAIL_CATEGORIES_ARGS
+Default arguments and options for sbank-detail-categories.
+sbank_DETAIL_NAMES_ARGS
+Default arguments and options for sbank-detail-names.
+sbank_DETAIL_MESSAGES_ARGS
+Default arguments and options for sbank-detail-messages.
+sbank_DETAIL_JOBS_ARGS
+Default arguments and options for sbank-detail-jobs.
+sbank_DETAIL_PROJECTS_ARGS
+Default arguments and options for sbank-detail-projects.
+sbank_DETAIL_TRANSACTIONS_ARGS
+Default arguments and options for sbank-detail-transactions.
+sbank_DETAIL_USERS_ARGS
+Default arguments and options for sbank-detail-users.
+sbank_LIST_ALLOCATIONS_ARGS
+Default arguments and options for sbank-list-allocations.
+sbank_LIST_JOBS_ARGS
+Default arguments and options for sbank-list-jobs.
+sbank_LIST_PROJECTS_ARGS
+Default arguments and options for sbank-list-projects.
+sbank_LIST_TRANSACTIONS_ARGS
+Default arguments and options for sbank-list-transactions.
+sbank_LIST_USERS_ARGS
+Default arguments and options for sbank-list-users.
+EXAMPLES
+Example 1: -f, --field
+
> sbank-list-transactions ... -f field1:-20 -f field2:20 -f field3 or > sbank-list-transactions ... -f "field1:-20 field2:20 field3"
+
Example 2: -S, -E, --created, --queued, --last-updated, --history-start, --history-end
+Single date-string examples:
+
+-
+
+sbank-list-allocations -S ">=Oct 11, 2014" start dates that are >= "2014-10-11 00:00:00"
+
+
+-
+
+sbank-list-allocations -S "<=2014-11-10" start dates that are <= "2014-11-10 00:00:00"
+
+
+-
+
+sbank-list-allocations -E "<20141110" end dates that are < "2014-11-10 00:00:00"
+
+
+-
+
+sbank-list-allocations -E "22:30:10" end dates that are < " 22:30:10"
+
+
+-
+
+sbank-list-allocations -S ">today" start dates that are > " 00:00:00"
+
+
+-
+
+sbank-list-allocations -E t end dates that are < " 00:00:00"
+
+
+-
+
+sbank-list-allocations -S gtnow start dates that are > " "
+
+
+-
+
+sbank-list-allocations -E len end dates that are <= " "
+
+
+-
+
+sbank-list-allocations -S "1d" start dates that are >= "today +1 day"
+
+
+-
+
+sbank-list-allocations -E "-2w" end dates that are < "today -2 weeks"
+
+
+-
+
+sbank-list-allocations -S ">=1y" start dates that are >= "today +1 year"
+
+
+-
+
+sbank-list-allocations -S ">2012" start dates that are > "2012-- 00:00:00"
+
+
+
+Range date-string examples:
+
+-
+
+sbank-list-allocations -S "2013-01-01...2014-01-01" "2013-01-01" <= DATES < "2014-01-01"
+
+
+-
+
+sbank-list-allocations -S "-1y...t" "today -1 year" <= DATES < "today"
+
+
+-
+
+sbank-list-allocations -E "2013...t"" "2013--" <= DATES < "today"
+
+
+-
+
+sbank-list-allocations -E ">2013...<=t"" "2013--" < DATES <= "today"
+
+
+
+Example 3: Command invocation examples
+
+-
+
+sbank-list-projects list projects full command invocation
+
+
+-
+
+sbank list projects list projects meta command invocation
+
+
+-
+
+sbank s p list projects partial meta command invocation
+
+
+-
+
+sbank p list projects where "list" is the default
+
+
+-
+
+sbank list allocations is the default
+
+
+-
+
+sbank a list allocations "list" is the default
+
+
+-
+
+sbank s a list allocations partial meta command invocation
+
+
+
+Example 4: -h, --help
+
+-
+
+sbank -h will give you help summary on all of sbank
+
+
+-
+
+sbank list --help will give you help on all the "list" commands
+
+
+-
+
+sbank list allocations -h will give you help on the "list allocations" command
+
+
+-
+
+sbank-list-allocations -h will give you help on the "list allocations" command
+
+
+-
+
+sbank l a --help will give you help on the "list allocations" command
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+  +
+  +Connection to one of the CS-2 cluster login nodes requires an MFA passcode for authentication - either an 8-digit passcode generated by an app on your mobile device (e.g. MobilePASS+) or a CRYPTOCard-generated passcode prefixed by a 4-digit pin. This is the same passcode used to authenticate into other ALCF systems, such as Theta and Cooley.
+Connection to one of the CS-2 cluster login nodes requires an MFA passcode for authentication - either an 8-digit passcode generated by an app on your mobile device (e.g. MobilePASS+) or a CRYPTOCard-generated passcode prefixed by a 4-digit pin. This is the same passcode used to authenticate into other ALCF systems, such as Theta and Cooley.

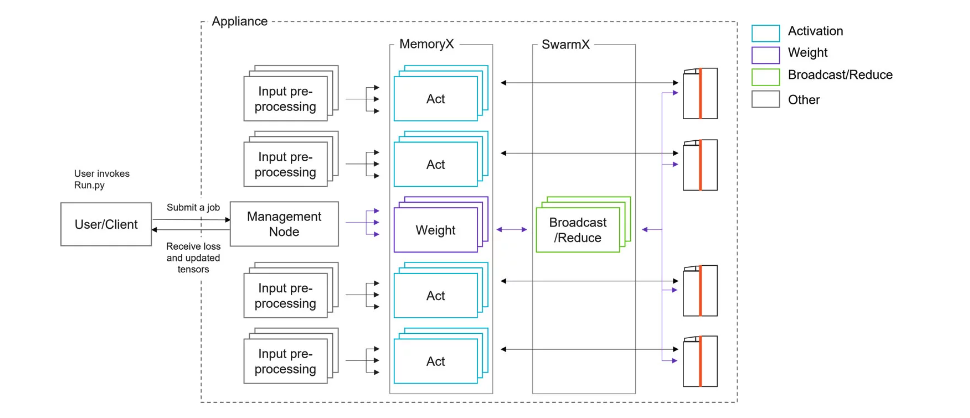 +
+ 

 +(Figure from
+
+(Figure from
+


