Note
An outline of the technical implementation of EDAM is below. EDAM makes light use of OWL logic/modelling and focuses on providing quality information for a basic set of concepts, with relations between these concepts and a very simple set of rules governing the conceptual relationships. Concepts have unique IDs and persistent URLs which resolve to a Web page providing all the information for that concept.
"A general bioinformatics subject or category, such as a field of study, data, processing, analysis or technology."
e.g. "Biology", "Nucleic acid sites, features and motifs", "Sequencing".
Topic concepts provide very broad categories for annotation of diverse bioinformatics resources. There will only ever be a few hundred EDAM topics: biology or computer science is not exhaustively covered!
"A function or process performed by a tool; what is done, but not (typically) how or in what context."
e.g. "Sequence alignment", "Genome indexing", "Sequence database search".
Operation concepts enable the annotation of software tool functions, from quite broad to very specific. There will be as many EDAM Operations as required to support pratical applications, e.g. description / finding tools in bio.tools.
"A type of data in common use in bioinformatics."
e.g. "Sequence alignment", "Comparison matrix", "Phylogenetic tree".
Data concepts enable the annotation of types of data, e.g. inputs and ouputs of tools. There are some categories of data (for structuring EDAM), and some common tool parameters, but mostly they correspond to specific data formats (see below), i.e. complex biological data. Note: a single type of data can be serialised in multiple data formats!
"A label that identifies (typically uniquely) something such as data, a resource or a biological entity."
e.g. "UniProt accession", "EC number", "Gene symbol".
Identifier concepts enable the annotation of identifiers of data. There are some categories (for structuring EDAM), but mostly they correspond to specific data identifiers. Identifiers are typically simple strings and EDAM includes regular expressions defining valid string values. Identifiers are formally related in EDAM to Data concepts (see is_identifier_of).
"A specific layout for encoding a specific type of data in a computer file or memory."
e.g. "FASTA format", "PDB format", "mmCIF".
Format concepts enable the annotation of specific data formats / syntaxes; some general purpose ones but mostly biological data formats.
To be included, a format must be in common use and formally specified or documented; EDAM includes links to these things. Formats are formally related in EDAM to Data concepts (see is_format_of).
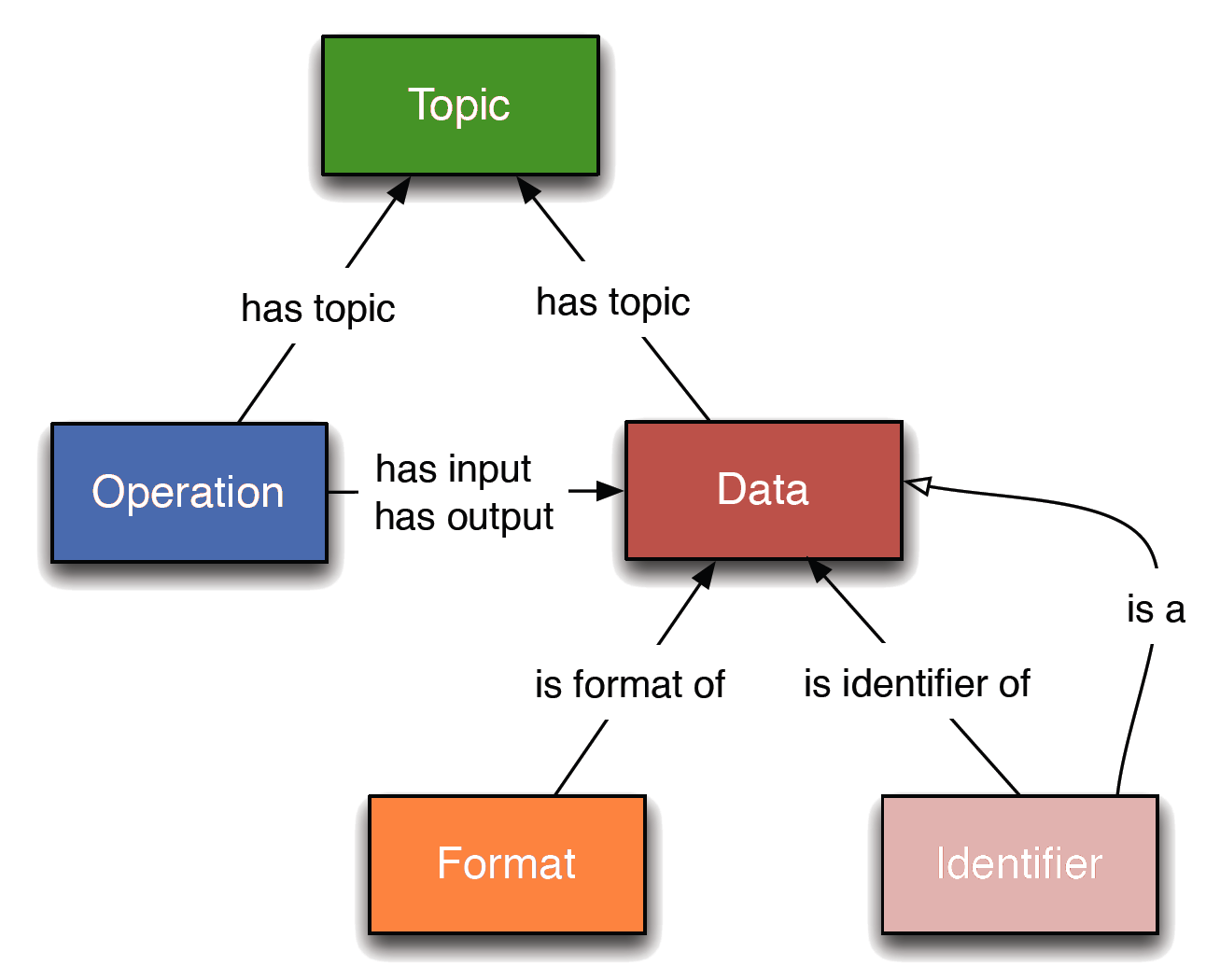
Defines a concept as a specialisation of another concept. If A is_a B, then A is a specialisation (child) of B, and B is a generalisation (parent) of A.
The is_a relation is transitive: if A is_a B and B is_a C then A is_a C.
All relations are transitive over is_a: e.g. if A has_input B and B is_a C then A has_input C, and if A is_a B and B has_input C then A has_input C.
e.g. "Pairwise sequence alignment" is_a "Sequence alignment"
Defines an Operation concept as reading (inputting) a Data concept.
e.g. "Sequence analysis" has_input "Sequence"
Defines an Operation concept as writing (outputting) a Data concept.
e.g. "Sequence alignment" has_output "Sequence alignment"
Defines a Data or Operation concept as being within the scope of a Topic concept.
e.g. "Peptide identification" has_topic "Proteomics"
Defines that an Identifier concept identifies a Data concept.
e.g. "Sequence accession" is_identifier_of "Sequence"
Defines that a Format concept is the format of a Data concept.
e.g. "Sequence record format" is_format_of "Sequence record"
Rules define how concepts are related.
Topic
- Topic is_a Topic (specialisation of a topic)
Operation
- Operation is_a Operation (specialisation of an operation)
- Operation has_input Data (inputs a type of data)
- Operation has_output Data (outputs a type of data)
- Operation has_topic Topic (within a topic)
Data
- Data is_a Data (specialisation of a type of data)
- Data has_topic Topic (within a topic)
Format
- Format is_a Format (specialisation of a data format)
- Format is_format_of Data (a format specification of a data type)
Identifier
- Identifier is_identifier_of Data (identifier of a data type)
is_a
- Topic is_a Topic
- Operation is_a Operation
- Data is_a Data
- Format is_a Format
has_input
- Operation has_input Data
has_output
- Operation has_output Data
has_topic
- Operation has_topic Topic
- Data has_topic Topic
is_identifier_of
- Identifier is_identifier_of Data
is_format_of
- Format is_format_of Data
EDAM concepts are defined internally (via <oboInOwl:inSubset>) as one of two types:
- Placeholder concepts are high-level (conceptually broad), and used primarily to structure EDAM, providing placeholders for concrete concepts. They're not intended to be used much, or at all, for annotation.
- Concrete concepts are lower-level (conceptually more narrow) and are intended for annotation. All leaf nodes are concrete.
These notions depend upon the subontology (see below).
Note
EDAM topics are conceptually very broad categories with no clearly defined borders between each other: the notion of placeholder and concrete concepts doesn't apply!
- Operation placeholders include high-level (abstract) operations e.g. Analysis, Prediction and recognition, and sometimes variants e.g. Sequence analysis.
- all Tier 1 (children of Operation) and some Tier 2 operations are placeholders
- Data placeholders include:
- basic technical types, e.g. Score
- broad biological types e.g. Phylogenetic data
- they mostly appear in Tier 1 (children of Operation), rarely in Tier 2, and never below that (note, not all Tier 1 Data concepts are placeholders)
- Identifier placeholders include:
- basic type one of Accession or Name. All concrete identifiers are a child of one of these.
- type of data under Identifier (by type of data) e.g. "Sequence accession (protein)". These mirror the Data subontology. All concrete identifiers are a child of one of these.
- Identifier (hybrid): a concrete identifier is a child of this if it's re-used for data objects of fundamentally different types (typically served from a single database)
- Format placeholders include:
- basic type currently Textual format, Binary format, XML, HTML, JSON, RDF format and YAML. All concrete formats are a child of one of these.
- type of data under Format (by type of data) e.g. Alignment format, Image format etc.. All concrete formats are a child of one of these.
Note
The data type placeholders used in the Identifier and Format subontologies reflect the EDAM Data subontology. They serve purely to aid navigation, by providing an additional axis over (the same set of) concepts under "Accesion" and "Name" (Identifier) or "Textual format", "Binary format", etc. (Format). Once ontology browsers better support rendering of conceptual relationships, it may no longer be necessary to support in EDAM the Format (by type of data) and Identifier (by type of data) patterns.
- Concrete operations
- have specific input(s) and/or output(s) (Operation has_input | has_output Data relation)
- include low-level (specific) operations (e.g. Protein feature detection) and in some cases variants (e.g. Protein binding site prediction) and sub-variants (e.g. Protein-nucleic acid binding prediction)
- Concrete data types
- have a specific serialisation format (Format is_format_of Data relation)
- Concrete identifers
- have a corresponding data type (Identifier is_identifier_of Data relation)
- normally have a regular expression pattern defining valid syntax of identifier instances (
<regex>attribute)
- Concrete data formats
- have a formal, public syntax specification (
<specification>attribute) - in some cases, as practical necessity, there are format variants and sub-variants, e.g. EMBL-like (XML) and FASTA-like (text)
- have a formal, public syntax specification (
Note
The notions of "placeholder", "concrete", "broad", "narrow" etc. are of course not hard and fast. As a work in progress, all placeholders and concrete concepts will be formally annotated as such, this under discussion. The addition of has_input and has_output relations is also a work in progress.
There are limitations on the number of placeholders, and concrete concepts, that are chained (via is_a relation) together. In practice, this results in a maximum depth of each subontology.
- Topic:
- each concept must have a path to root not exceeding 4 levels, e.g. Topic -> "Computational biology" -> "Molecular genetics" -> "Gene structure" -> "Mobile genetic elements"
- 5 levels deep max. (in exceptional circumstances, an alternative path to root may exist, but never deeper than 5 levels)
- Operation:
- maximum chain of 3 placeholders
- maximum chain of 3 concrete operations
- thus 6 levels deep max.
- Data:
- maximum chain of 2 placeholders
- maximum chain of 2 concrete data types
- thus 4 levels deep max.
- Identifier:
- maximum chain of 4 placeholders, e.g. Identifier (by type of data) -> "Sequence identifier" -> "Sequence accession" -> "Sequence accession (protein)"
- maximum chain of 2 concrete identifiers
- thus 6 levels deep max.
- Format:
- maximum chain of 4 placeholders, e.g. Format (by type of data) -> "Sequence record format" -> "FASTA-like" -> "FASTA-like (text)"
- maximum chain of 2 concrete formats
- thus 6 levels deep max.
EDAM uses:
- Exact synonym - a standard synonym (same meaning) of the primary term
- Narrow synonym - specialisms of the primary term
- Broad synonym - generalisations of the primary term (used in exceptional cases only)
All terms (primary and synonyms) are unique within a subontology, and (with a few exceptions) are unique between subontologies, too.
<todo>
Each EDAM concept has an alphanumerical identifier that uniquely identifies that concept. The general form is:
<namespace>_<4-digit-ID>
where <namespace> refers to an EDAM subontology, one of:
topicoperationdataformat
and <4-digit-ID> uses numbers from 0 to 9. Note this number is unique across all subontologies.
The IDs are used in URLs that resolve to information about the concept, e.g.:
topic_0121- http://edamontology.org/topic_0121
These identifiers (and the URLs) persist between versions: a given ID and URI are guaranteed to continue identifying the same concept. This does not imply that terms, definitions and other information remains constant, but the IDs will remain essentially true to the original concept.
Occasionally, concepts become deprecated - designated as not being recommended for use. Deprecated concepts also persist; they are removed and will maintain their ID and URI. EDAM developers adhere to rules on deprecatation, e.g. a replacement concept, or suggested replacement is given for all deprecated concepts.
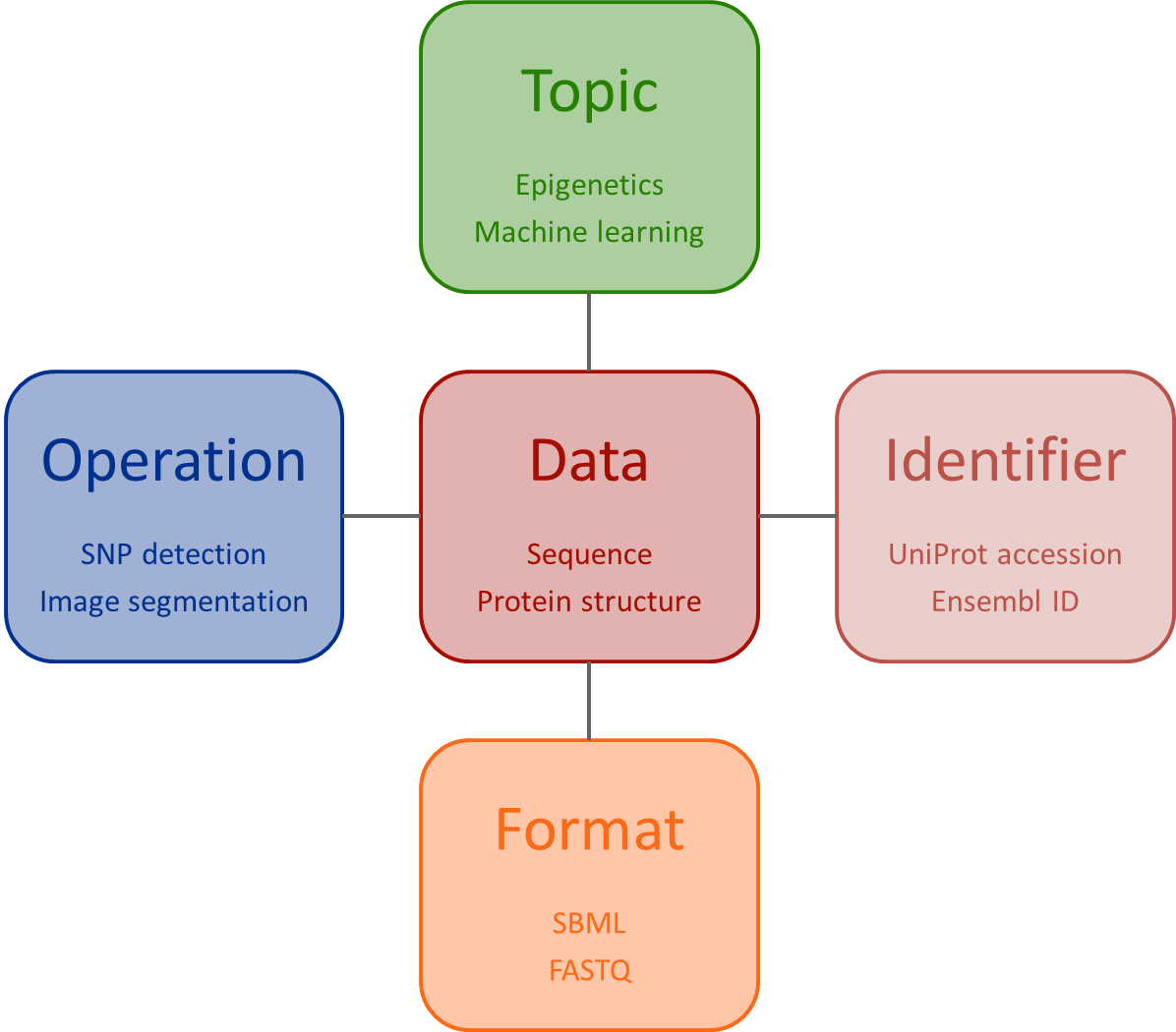
In order to propose a coherent experience in environments using the EDAM Ontology, a color sheme have been chosen and it is recommended to use it. Images the color scheme can be found here and there.
{kind=link}
{kind=link}
| Branch | Color | Light color |
|---|---|---|
| Data | #a7544d | #d6b1ae |
| Identifier | #d6b1ae | #e2cdcb |
| Topic | #5f903d | #b4cca1 |
| Operation | #556ca9 | #a3b0d1 |
| Format | #e6834c | #f2c4a9 |
| Deprecated | #999999 | #bbb |