Experiment tracking for scikit-learn–trained models.
- Log, organize, visualize, and compare ML experiments in a single place
- Monitor model training live
- Version and query production-ready models and associated metadata (e.g., datasets)
- Collaborate with the team and across the organization
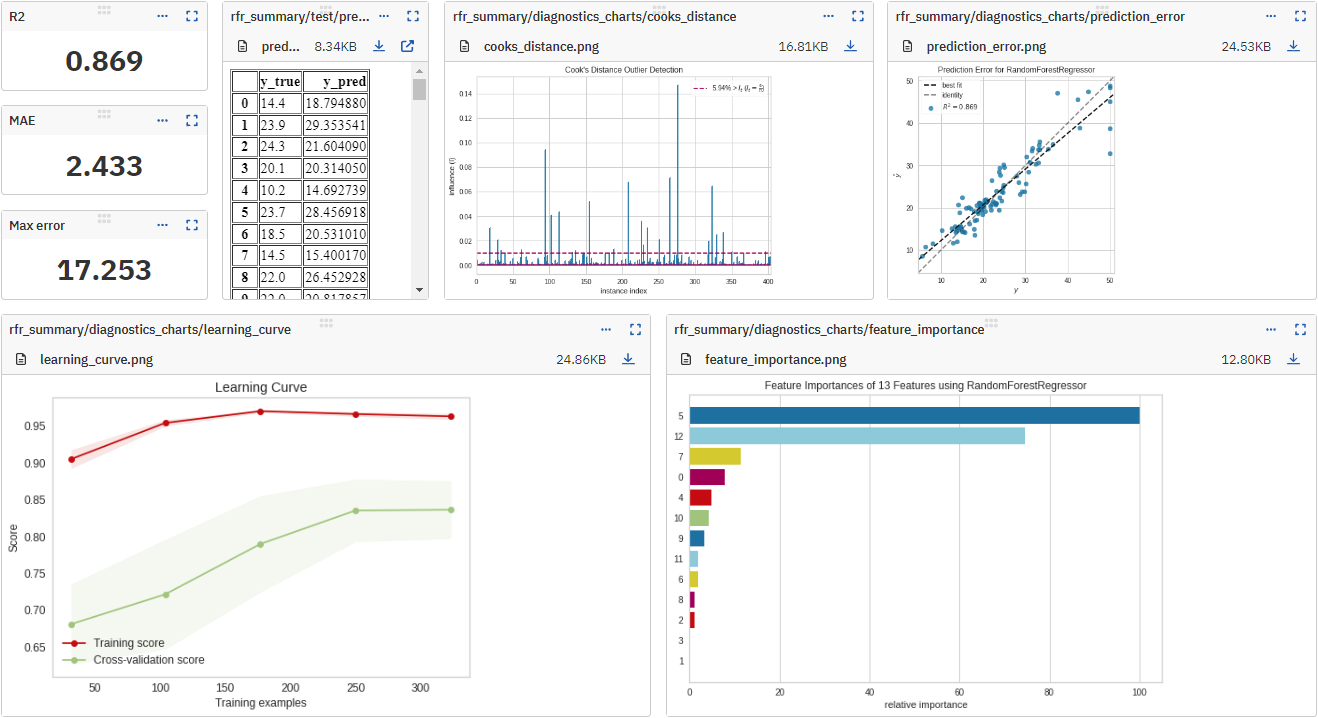
- classifier and regressor parameters,
- pickled model,
- test predictions,
- test predictions probabilities,
- test scores,
- classifier and regressor visualizations, like confusion matrix, precision-recall chart, and feature importance chart,
- KMeans cluster labels and clustering visualizations,
- metadata including git summary info,
- other metadata
# On the command line:
pip install neptune-sklearn
# In Python, prepare a fitted estimator
parameters = {
"n_estimators": 70, "max_depth": 7, "min_samples_split": 3
}
estimator = ...
estimator.fit(X_train, y_train)
# Import Neptune and start a run
import neptune
run = neptune.init_run(
project="common/sklearn-integration",
api_token=neptune.ANONYMOUS_API_TOKEN,
)
# Log parameters and scores
run["parameters"] = parameters
y_pred = estimator.predict(X_test)
run["scores/max_error"] = max_error(y_test, y_pred)
run["scores/mean_absolute_error"] = mean_absolute_error(y_test, y_pred)
run["scores/r2_score"] = r2_score(y_test, y_pred)
# Stop the run
run.stop()If you got stuck or simply want to talk to us, here are your options:
- Check our FAQ page
- You can submit bug reports, feature requests, or contributions directly to the repository.
- Chat! When in the Neptune application click on the blue message icon in the bottom-right corner and send a message. A real person will talk to you ASAP (typically very ASAP),
- You can just shoot us an email at [email protected]