


skfolio is a Python library for portfolio optimization built on top of scikit-learn. It offers a unified interface and tools compatible with scikit-learn to build, fine-tune, and cross-validate portfolio models.
It is distributed under the open source 3-Clause BSD license.
- Documentation: https://skfolio.org/
- Examples: https://skfolio.org/auto_examples/
- User Guide: https://skfolio.org/user_guide/
- GitHub Repo: https://github.com/skfolio/skfolio/
skfolio is available on PyPI and can be installed with:
pip install -U skfolio
skfolio requires:
- python (>= 3.10)
- numpy (>= 1.23.4)
- scipy (>= 1.8.0)
- pandas (>= 1.4.1)
- cvxpy (>= 1.4.1)
- scikit-learn (>= 1.5.0)
- joblib (>= 1.3.2)
- plotly (>= 5.22.0)
Since the development of modern portfolio theory by Markowitz (1952), mean-variance optimization (MVO) has received considerable attention.
Unfortunately, it faces a number of shortcomings, including high sensitivity to the input parameters (expected returns and covariance), weight concentration, high turnover, and poor out-of-sample performance.
It is well known that naive allocation (1/N, inverse-vol, etc.) tends to outperform MVO out-of-sample (DeMiguel, 2007).
Numerous approaches have been developed to alleviate these shortcomings (shrinkage, additional constraints, regularization, uncertainty set, higher moments, Bayesian approaches, coherent risk measures, left-tail risk optimization, distributionally robust optimization, factor model, risk-parity, hierarchical clustering, ensemble methods, pre-selection, etc.).
With this large number of methods, added to the fact that they can be composed together, there is a need for a unified framework with a machine learning approach to perform model selection, validation, and parameter tuning while reducing the risk of data leakage and overfitting.
This framework is built on scikit-learn's API.
- Portfolio Optimization:
- Naive:
- Equal-Weighted
- Inverse-Volatility
- Random (Dirichlet)
- Convex:
- Mean-Risk
- Risk Budgeting
- Maximum Diversification
- Distributionally Robust CVaR
- Clustering:
- Hierarchical Risk Parity
- Hierarchical Equal Risk Contribution
- Nested Clusters Optimization
- Ensemble Methods:
- Stacking Optimization
- Expected Returns Estimator:
- Empirical
- Exponentially Weighted
- Equilibrium
- Shrinkage
- Covariance Estimator:
- Empirical
- Gerber
- Denoising
- Detoning
- Exponentially Weighted
- Ledoit-Wolf
- Oracle Approximating Shrinkage
- Shrunk Covariance
- Graphical Lasso CV
- Implied Covariance
- Distance Estimator:
- Pearson Distance
- Kendall Distance
- Spearman Distance
- Covariance Distance (based on any of the above covariance estimators)
- Distance Correlation
- Variation of Information
- Prior Estimator:
- Empirical
- Black & Litterman
- Factor Model
- Uncertainty Set Estimator:
- On Expected Returns:
- Empirical
- Circular Bootstrap
- On Covariance:
- Empirical
- Circular bootstrap
- Pre-Selection Transformer:
- Non-Dominated Selection
- Select K Extremes (Best or Worst)
- Drop Highly Correlated Assets
- Cross-Validation and Model Selection:
- Compatible with all sklearn methods (KFold, etc.)
- Walk Forward
- Combinatorial Purged Cross-Validation
- Hyper-Parameter Tuning:
- Compatible with all sklearn methods (GridSearchCV, RandomizedSearchCV)
- Risk Measures:
- Variance
- Semi-Variance
- Mean Absolute Deviation
- First Lower Partial Moment
- CVaR (Conditional Value at Risk)
- EVaR (Entropic Value at Risk)
- Worst Realization
- CDaR (Conditional Drawdown at Risk)
- Maximum Drawdown
- Average Drawdown
- EDaR (Entropic Drawdown at Risk)
- Ulcer Index
- Gini Mean Difference
- Value at Risk
- Drawdown at Risk
- Entropic Risk Measure
- Fourth Central Moment
- Fourth Lower Partial Moment
- Skew
- Kurtosis
- Optimization Features:
- Minimize Risk
- Maximize Returns
- Maximize Utility
- Maximize Ratio
- Transaction Costs
- Management Fees
- L1 and L2 Regularization
- Weight Constraints
- Group Constraints
- Budget Constraints
- Tracking Error Constraints
- Turnover Constraints
The code snippets below are designed to introduce the functionality of skfolio so you can start using it quickly. It follows the same API as scikit-learn.
from sklearn import set_config
from sklearn.model_selection import (
GridSearchCV,
KFold,
RandomizedSearchCV,
train_test_split,
)
from sklearn.pipeline import Pipeline
from scipy.stats import loguniform
from skfolio import RatioMeasure, RiskMeasure
from skfolio.datasets import load_factors_dataset, load_sp500_dataset
from skfolio.model_selection import (
CombinatorialPurgedCV,
WalkForward,
cross_val_predict,
)
from skfolio.moments import (
DenoiseCovariance,
DetoneCovariance,
EWMu,
GerberCovariance,
ShrunkMu,
)
from skfolio.optimization import (
MeanRisk,
NestedClustersOptimization,
ObjectiveFunction,
RiskBudgeting,
)
from skfolio.pre_selection import SelectKExtremes
from skfolio.preprocessing import prices_to_returns
from skfolio.prior import BlackLitterman, EmpiricalPrior, FactorModel
from skfolio.uncertainty_set import BootstrapMuUncertaintySetprices = load_sp500_dataset()X = prices_to_returns(prices)
X_train, X_test = train_test_split(X, test_size=0.33, shuffle=False)model = MeanRisk()model.fit(X_train)
print(model.weights_)portfolio = model.predict(X_test)
print(portfolio.annualized_sharpe_ratio)
print(portfolio.summary())model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
risk_measure=RiskMeasure.SEMI_VARIANCE,
)model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
prior_estimator=EmpiricalPrior(
mu_estimator=ShrunkMu(), covariance_estimator=DenoiseCovariance()
),
)model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
mu_uncertainty_set_estimator=BootstrapMuUncertaintySet(),
)model = MeanRisk(
min_weights={"AAPL": 0.10, "JPM": 0.05},
max_weights=0.8,
transaction_costs={"AAPL": 0.0001, "RRC": 0.0002},
groups=[
["Equity"] * 3 + ["Fund"] * 5 + ["Bond"] * 12,
["US"] * 2 + ["Europe"] * 8 + ["Japan"] * 10,
],
linear_constraints=[
"Equity <= 0.5 * Bond",
"US >= 0.1",
"Europe >= 0.5 * Fund",
"Japan <= 1",
],
)
model.fit(X_train)model = RiskBudgeting(risk_measure=RiskMeasure.CVAR)model = RiskBudgeting(
prior_estimator=EmpiricalPrior(covariance_estimator=GerberCovariance())
)model = NestedClustersOptimization(
inner_estimator=MeanRisk(risk_measure=RiskMeasure.CVAR),
outer_estimator=RiskBudgeting(risk_measure=RiskMeasure.VARIANCE),
cv=KFold(),
n_jobs=-1,
)randomized_search = RandomizedSearchCV(
estimator=MeanRisk(),
cv=WalkForward(train_size=252, test_size=60),
param_distributions={
"l2_coef": loguniform(1e-3, 1e-1),
},
)
randomized_search.fit(X_train)
best_model = randomized_search.best_estimator_
print(best_model.weights_)model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
risk_measure=RiskMeasure.VARIANCE,
prior_estimator=EmpiricalPrior(mu_estimator=EWMu(alpha=0.2)),
)
print(model.get_params(deep=True))
gs = GridSearchCV(
estimator=model,
cv=KFold(n_splits=5, shuffle=False),
n_jobs=-1,
param_grid={
"risk_measure": [
RiskMeasure.VARIANCE,
RiskMeasure.CVAR,
RiskMeasure.VARIANCE.CDAR,
],
"prior_estimator__mu_estimator__alpha": [0.05, 0.1, 0.2, 0.5],
},
)
gs.fit(X)
best_model = gs.best_estimator_
print(best_model.weights_)views = ["AAPL - BBY == 0.03 ", "CVX - KO == 0.04", "MSFT == 0.06 "]
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
prior_estimator=BlackLitterman(views=views),
)factor_prices = load_factors_dataset()
X, y = prices_to_returns(prices, factor_prices)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, shuffle=False)
model = MeanRisk(prior_estimator=FactorModel())
model.fit(X_train, y_train)
print(model.weights_)
portfolio = model.predict(X_test)
print(portfolio.calmar_ratio)
print(portfolio.summary())model = MeanRisk(
prior_estimator=FactorModel(
factor_prior_estimator=EmpiricalPrior(covariance_estimator=DetoneCovariance())
)
)factor_views = ["MTUM - QUAL == 0.03 ", "VLUE == 0.06"]
model = MeanRisk(
objective_function=ObjectiveFunction.MAXIMIZE_RATIO,
prior_estimator=FactorModel(
factor_prior_estimator=BlackLitterman(views=factor_views),
),
)set_config(transform_output="pandas")
model = Pipeline(
[
("pre_selection", SelectKExtremes(k=10, highest=True)),
("optimization", MeanRisk()),
]
)
model.fit(X_train)
portfolio = model.predict(X_test)model = MeanRisk()
mmp = cross_val_predict(model, X_test, cv=KFold(n_splits=5))
# mmp is the predicted MultiPeriodPortfolio object composed of 5 Portfolios (1 per testing fold)
mmp.plot_cumulative_returns()
print(mmp.summary())model = MeanRisk()
cv = CombinatorialPurgedCV(n_folds=10, n_test_folds=2)
print(cv.get_summary(X_train))
population = cross_val_predict(model, X_train, cv=cv)
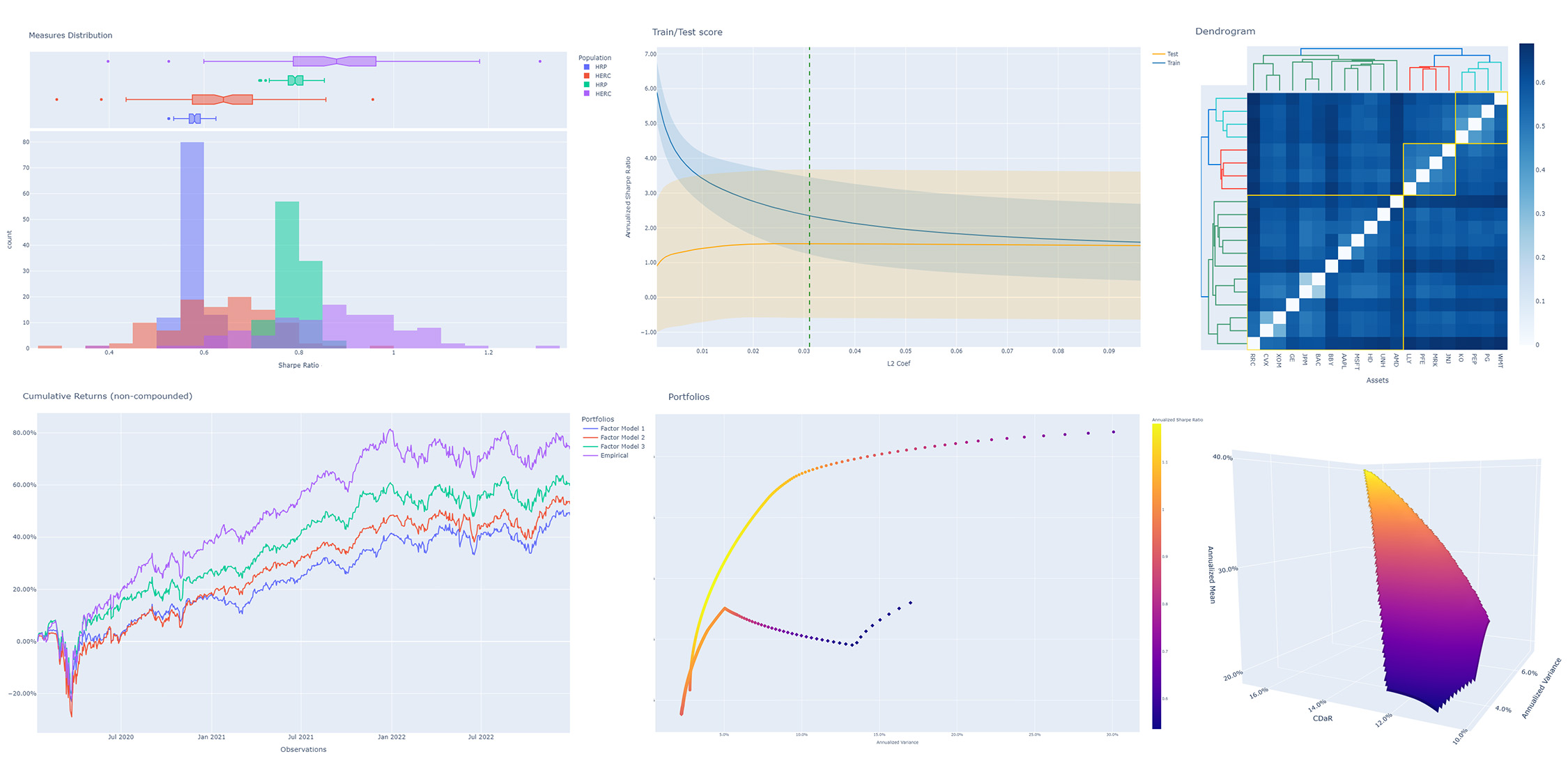
population.plot_distribution(
measure_list=[RatioMeasure.SHARPE_RATIO, RatioMeasure.SORTINO_RATIO]
)
population.plot_cumulative_returns()
print(population.summary())We would like to thank all contributors behind our direct dependencies, such as scikit-learn and cvxpy, but also the contributors of the following resources that were a source of inspiration:
- PyPortfolioOpt
- Riskfolio-Lib
- scikit-portfolio
- microprediction
- statsmodels
- rsome
- gautier.marti.ai
If you use skfolio in a scientific publication, we would appreciate citations:
Bibtex entry:
@misc{skfolio,
author = {Delatte, Hugo and Nicolini, Carlo},
title = {skfolio},
year = {2023},
url = {https://github.com/skfolio/skfolio}
}