Home
Un compilateur est un programme qui prend en entrée un fichier source et qui produit en sortie un fichier exécutable. Pour cela, il effectue plusieurs étapes :
-
Analyse lexicale : le compilateur découpe le fichier source en une suite de lexèmes (ou tokens). Par exemple, le code
int a = 42;sera découpé en 5 lexèmes :int,a,=,42et;. -
Analyse synthaxique : Le compilateur analyse la structure du code source et construit un arbre de syntaxe abstraite (AST). Par exemple, le code
int a = 42;sera transformé en un arbre de syntaxe abstraite qui contient un noeudintqui a pour fils un noeudaet un noeud42qui a pour fils un noeud=. Le noeud=a pour fils un noeudintet un noeud;. -
Analyse sémantique : Le compilateur vérifie que le code source est valide. Par exemple, le code
int a = 42;est valide, mais le codeint a = a ;ne l'est pas. -
Génération de code : Le compilateur génère le code assembleur correspondant au code source. Par exemple, le code
int a = 42;sera transformé enmov eax, 42. -
Optimisation : Le compilateur optimise le code assembleur généré. Par exemple, le code
mov eax, 42sera transformé enmov eax, 2Ah. - Génération de l'exécutable : Le compilateur génère l'exécutable à partir du code assembleur optimisé.
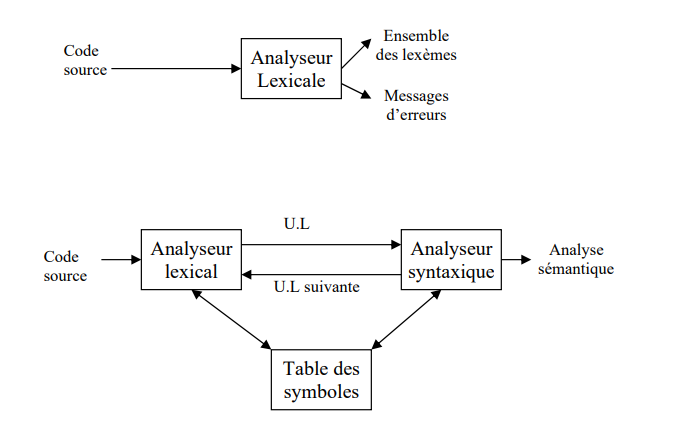
L'analyse lexicale consiste à découper le code source en une suite de lexèmes (ou tokens) avant de l'envoyer à l'analyseur syntaxique.
L'analyseur lexicale est un automate à états finis qui va lire le code source caractère par caractère et qui va construire les lexèmes un par un. Pour cela, il va utiliser une table de transition qui va lui permettre de savoir quel est le prochain état à atteindre en fonction du caractère lu et de l'état actuel.
Il se charge aussi de faire le tri entre les lexèmes qui sont utiles pour l'analyseur syntaxique et ceux qui ne le sont pas. Par exemple, les espaces, les tabulations et les retours à la ligne ne sont pas utiles pour l'analyseur syntaxique, donc l'analyseur lexicale va les ignorer.
Un lexème est une suite de caractères qui a un sens pour le compilateur. Par exemple, le code int a = 42; sera découpé en 5 lexèmes : int, a, =, 42 et ;.
Une unité lexicale est un ensemble de lexèmes qui ont le même sens pour le compilateur. Par exemple, les lexèmes int, char, float et double sont des lexèmes qui ont le même sens pour le compilateur, car ils représentent tous des types de données. On peut donc les regrouper dans une même unité lexicale qui s'appelle TYPE.
Un modèle de règle lexicale est une expression régulière qui permet de définir un ensemble de lexèmes. Par exemple, le modèle de règle lexicale [a-zA-Z][a-zA-Z0-9]* permet de définir l'ensemble des identifiants valides en C.
Un attribut est un ensemble d'information concernant le lexème.
Les erreurs à ce niveau là de la compilation sont rares mais peuvent arriver, à ça deux stratégies :
- Mode panique : On ignore simplement l'erreur lexicale et on réattribut le travail de détection à l'analyseur synthaxique.
- Correction locale : La correction locale est une technique de récupération sur erreur. Lorsqu'un analyseur constate une erreur lors de la lecture d'un symbole, il remplace le symbole lu par un autre qui lui semble plus juste. Implémentation possible en calculant le nombre de transformation possible avant de passer d'un mot qui pose problème à un mot qui n'en pose pas.
La correction locale propose une solution coûteuse en terme de temps de compilation contrairement au mode panique qui propose ici une solution brute, simple et rapide. Nous allons donc le choisir.

L'analyse syntaxique consiste à analyser la structure du code source et à construire un arbre de syntaxe abstraite (AST).
Elle a pour rôle la vérification de la forme ou encore la bonne disposition de de la suite des entités lexicale, on parlera alors de la syntaxe du langage. La vérification est faite à l'aide de la grammaire spécifique au langage appelée grammaire syntaxique.
Une grammaire syntaxique est un ensemble de règles qui permettent de définir la syntaxe d'un langage. Par exemple, la grammaire syntaxique du langage C est la suivante :
programme → déclaration
déclaration → déclaration_variable | déclaration_fonction
déclaration_variable → type identificateur ;
déclaration_fonction → type identificateur ( liste_paramètres ) { liste_instructions }
liste_paramètres → paramètre | paramètre , liste_paramètres
paramètre → type identificateur
liste_instructions → instruction | instruction liste_instructions
instruction → instruction_conditionnelle | instruction_iteration | instruction_saut | instruction_expression ;
etc...Il existe deux méthodes d'analyse syntaxique :
- Analyse syntaxique descendante : L'analyseur syntaxique va essayer de transformer le code source en un arbre de syntaxe abstraite en partant de la racine de l'arbre et en descendant jusqu'aux feuilles. Pour cela, il va utiliser la grammaire syntaxique du langage. Cette méthode est aussi appelée analyse LL.
- Analyse synthaxique ascendante : L'analyseur syntaxique va essayer de transformer le code source en un arbre de syntaxe abstraite en partant des feuilles de l'arbre et en remontant jusqu'à la racine. Pour cela, il va utiliser la grammaire syntaxique du langage. Cette méthode est aussi appelée analyse LR.
Un arbre de syntaxe abstraite (AST) est un arbre qui représente la structure du code source. Chaque nœud de l'arbre représente une entité syntaxique du code source.
En analayse syntaxique, les erreurs sont plus fréquentes qu'en analyse lexicale. Il existe quatres stratégies pour gérer les erreurs syntaxiques :
- Mode panique : L'analyseur supprime un à un chaque prochain symbole jusqu'à ce qu'il atteigne un symbole permettant de se resynchroniser.
- Production d'erreur : L'analyseur produit une erreur et passe à la suite.
- Correction locale : L'analyseur supprime un à un chaque prochain symbole jusqu'à ce qu'il atteigne un symbole permettant de se resynchroniser. Il remplace ensuite le symbole lu par un autre qui lui semble plus juste. Par exemple remplacer une virgule par un point virgule.
- Correction globale : L'analyseur modifie une chaîne grâce à un algorithme qui effectue le nombre minimum d'opérations sur une chaîne erronée pour obtenir une chaîne correcte.
L'analyse sémantique consiste à analyser le sens du code source et à vérifier que le code source est cohérent. Par exemple, l'analyseur sémantique va vérifier que les types des opérandes sont compatibles avec l'opérateur utilisé.
La table des symboles est une structure de données qui permet de stocker les informations concernant les identificateurs. Par exemple, pour l'instruction int a = 42;, la table des symboles va contenir une entrée pour l'identificateur a qui va contenir les informations suivantes :
- Le nom de l'identificateur :
a - Le type de l'identificateur :
int - La valeur de l'identificateur :
42
Il y a plusieurs types d'identificateurs :
- Les variables :
int a = 42; - Les fonctions :
int main() { return 0; } - Les constantes :
const int a = 42; - Les types :
typedef int entier;
Il y a plusieurs types de table des symboles :
- Les mots-clefs : Mot réservé par le langage (Ex :
int,float,if,else,while,foretc...) - Les identifiants : Mot utilisé pour nommer une variable, une fonction, une constante ou un type, choisi par l'utilisateur, ne doit pas être un mot-clef.
- Les ponctuations :
;,,,(,),{,},[,],etc... - Les opérateurs : Symboles permettant d'appliquer une opération à des arguments renvoyant un résultat (Ex :
+,-,*,/,=,==,!=,>,<,>=,<=,etc...) - Les littéraux : Suite de caractère représentant une valeur logique. (Ex:
6.02e23,"music",true,false,etc...)
Les erreurs reconnues par l'analyseur sémantique sont :
- Déclaration d'un identificateur déjà déclaré : L'identificateur a déjà été déclaré dans le même bloc.
- Utilisation d'un identificateur non déclaré : L'identificateur n'a pas été déclaré dans le même bloc.
- Incompatibilité de type : Les types des opérandes ne sont pas compatibles avec l'opérateur utilisé.
- Utilisation abusive d'un mot-clef : Le mot-clef est utilisé dans un contexte où il n'est pas autorisé.
- Utilisation abusive d'un opérateur : L'opérateur est utilisé dans un contexte où il n'est pas autorisé.
- etc...
Le générateur de code natif est un programme qui va transformer l'arbre de syntaxe abstraite en code machine. Il existe deux méthodes pour générer du code machine :
- Génération de code machine directe : Le générateur de code machine va transformer l'arbre de syntaxe abstraite en code machine directement. Cette méthode est aussi appelée compilation.
- Génération de code assembleur : Le générateur de code machine va transformer l'arbre de syntaxe abstraite en code assembleur. Le code assembleur est ensuite transformé en code machine par un programme appelé assembleur. Cette méthode est aussi appelée assemblage.
Le code machine est un code binaire qui est directement exécutable par le processeur.
Le code assembleur est un code mnémonique qui est transformé en code machine par un programme appelé assembleur. Il est composé d'instructions et d'opérandes. Il existe plusieurs types d'instructions :
- Les instructions de transfert de contrôle :
jmp,jz,jnz,etc... - Les instructions arithmétiques :
add,sub,mul,div,etc... - Les instructions logiques :
and,or,xor,not,etc... - Les instructions de déplacement :
mov,push,pop,etc... - Les instructions de comparaison :
cmp,test,etc... - Les instructions de gestion de la pile :
call,ret,etc... - Et beaucoup d'autres...
L'optimiseur est un programme qui va transformer le code machine ou le code assembleur en un code machine ou un code assembleur plus optimisé. Il existe plusieurs types d'optimisations :
- Optimisation de la taille du code : L'optimiseur va transformer le code machine ou le code assembleur en un code machine ou un code assembleur plus petit.
- Optimisation de la vitesse d'exécution : L'optimiseur va transformer le code machine ou le code assembleur en un code machine ou un code assembleur plus rapide.
- Optimisation de la consommation d'énergie : L'optimiseur va transformer le code machine ou le code assembleur en un code machine ou un code assembleur qui consomme moins d'énergie.
Le débogueur est un programme qui permet d'exécuter le code machine ou le code assembleur pas à pas. Il permet de visualiser l'état du processeur à chaque étape de l'exécution du programme. Il permet aussi de visualiser la mémoire du processeur à chaque étape de l'exécution du programme.
L'executable est un fichier qui contient le code machine ou le code assembleur. Il est directement exécutable par le processeur. Il est généré par le générateur de code natif.