Note: Users are suggested to refer to the research paper to appear in ICPC 2022 by Bin Hu, Yijian Wu, Xin Peng, et al. Predicting Change Propagation between Code Clone Instances by Graph-based Deep Learning. Pre-assigned DOI: https://doi.org/10.1145/3524610.3527766
The dataset is evolving! Please direct your comments and suggestions to Yijian ([email protected]).
├── dataset
├── cloneGenealogy
├── basic_info.csv
├── consistent.csv
├── inconsistent.csv
├── res
├── project1
├── project2
└── ...
└── ...
└── FC-PDG
└── ...
├── saveModels
├── src
├── gcn.py
└── run.sh
└── README.md
The resource in this dataset contains 22,009 clone genealogies, 24,672 pairs of matched changes and 38,041 non-matched changes.
cloneGenealogy folder contains a web-based tool which can be used to show the source code changes in a clone pair genealogy.
The dataset was collected from 51 popular open-source Java projects. basic_info.csv details the information of these projects.
consistent.csvand inconsistent.csv contains matched change pairs and non-matched change pairs seperately.
res folder contains the clone genealogies extracted from each project.
FC-PDG folder contains the FC-PDGs extracted from the the above-mentioned clone genealogies.
File consistent.csv(or inconsistent.csv) contains all the matched(or non-matched) changes. The meaning of the headers lists as below:
- project: which project does the data belongs to
- groupId: the group id of the clone pair from which the data extracted
- clone type: the type of the clone pair before changed
- consistId: incremental id of the dataset
- consistGroup: ids of the matched clone pair. In one certain clone pair genealogy, the entity of the clone instance in each revision was given an unique number. Suppose a consistGroup like 3#4, if it is a matched change pair, it means that instance marked as 3 and instantce marked as 4 both experienced the same change, if it is a non-matched change, it means that instance marked as 3 changed while instance marked as 4 experienced a different change or non-changed.
- fileNum: 1 means the clone pair locates in the same file, 2 means the clone pair locates in different files.
The genealogy of each clone pair is stored in json file, which could be visualized in the web page. Here gives an instruction of the usage of these resources.

The above figure shows a matched change pair from dbeaver. It was extracted from the genealogy of clone pair 10585. Before changed, the clone pair was a type2 clone and the two instances were located in the same source file. Then, we open the web page CloneCoChange.html, select dbeaver and input 10585, the web shows a page as the picture below.
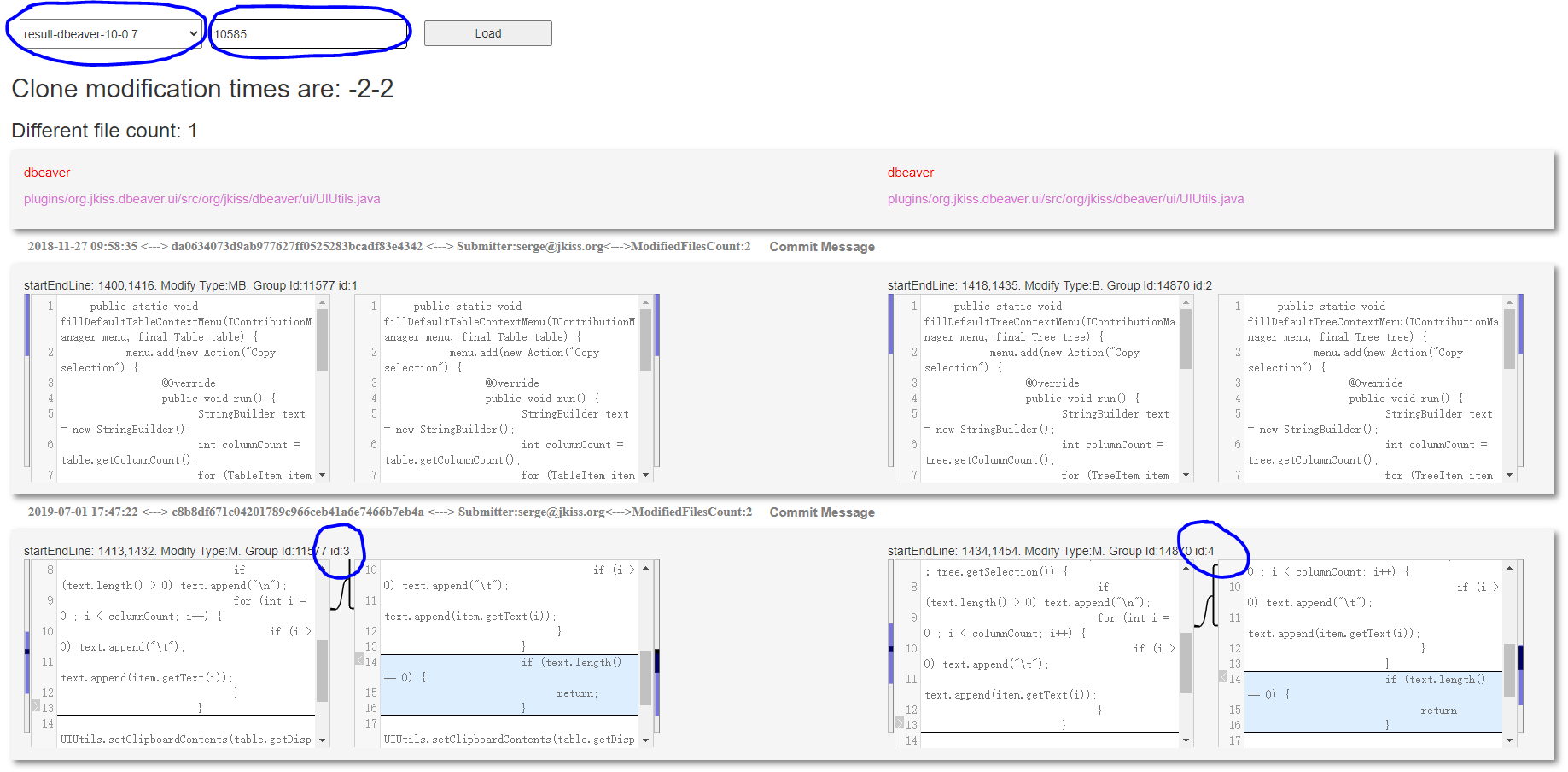
The picture above shows a clone genealogy of clone pair 10585. Each column presents an evolution timeline of one clone instance, each row presents the source code of two clone instance in the same revision.
As shown in the figure, the ids of the matched change pair were marked by blue circle, meaning that these two codes did the same change.
Requires Python 3.9+, Cuda 11.6+
Tested in conda with Python 3.9.15 and Pytorch 1.13.1
cd src
conda env create -f environment.yml
pip install -r requirements.txtmkdir ../saveModels
sh run.sh