{kind=link}
{kind=link}
{kind=link}
![]()
It is increasingly becoming difficult for human beings to work on their day to day life without going through the process of reverse Turing test, where the Computers tests the users to be humans or not. Almost every website and service providers today have the process of checking whether their website is being crawled or not by automated bots which could extract valuable information from their site. In the process the bots are getting more intelligent by the use of Deep Learning techniques to decipher those tests and gain unwanted automated access to data while create nuisance by posting spam. Humans spend a considerable amount of time almost every day when trying to decipher CAPTCHAs. The aim of this investigation is to check whether the use of a subset of commonly used CAPTCHAs, known as the text CAPTCHA is a reliable process for verifying their human customers. We mainly focused on the preprocessing step for every CAPTCHA which converts them in binary intensity and removes the confusion as much as possible and developed various models to correctly label as many CAPTCHAs as possible. We also suggested some ways to improve the process of verifying the humans which makes it easy for humans to solve the existing CAPTCHAs and difficult for bots to do the same.
We have build many models to solve some of the difficult open sourced CAPTCHAs that are available on the internet. We have obtained about more than 99.5% accuracy on most of the models, which converges at about 5 epochs. The generators folder have some of the modified codes that we have used to generate the data to feed into the model. The pyfiles folder section have all of the models and their corresponding python codes.
| CAPTCHA name | CAPTCHA img | Algorithm used | Accuracy Obtained | Try out in Google Colab |
|---|---|---|---|---|
| JAM CAPTCHA |  |
kNN | 99.53% |  |
| CNN_c4l_16x16_550 | 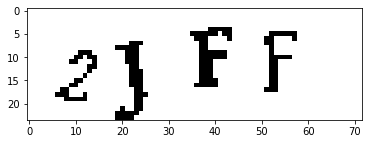 |
CNN - modified CIFAR 10 | 99.91% | |
| captcha-1L |  |
Own CNN model - multilabel classification | 99.67% | |
| captcha_4_letter |  |
LSTM model - multilabel classification | 99.87% | |
| captcha_v2 |  |
Own CNN - multilabel classification | 90.102% | |
| circle_captcha |  |
Alex Net with multilabel classification | 99.99% | |
| faded |  |
Alex Net with multilabel classification | 99.44% | |
| fish_eye |  |
Alex Net with multilabel classification | 99.46% | |
| mini_captcha |  |
Alex Net with multilabel classification | 97.25% | |
| multicolor | 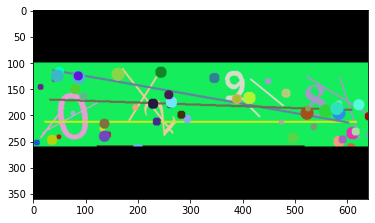 |
Alex Net with multilabel classification | 95.69% | |
| railway_captcha | 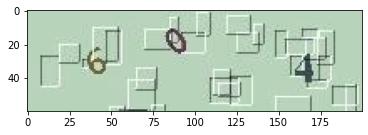 |
Own CNN model | 99.94% | |
| sphinx |  |
Alex Net with multilabel classification | 99.62% | |
[Thesis - Deceiving computers in Reverse Turing Test through Deep Learning (Research paper)] | [Slides]
Frequently Asked Questions
-
Are these the only notebooks?
- No, https://colab.research.google.com/github/Jimut123/CAPTCHA/blob/master/pyfiles/sphinx/sphinx_33_10e_9873.ipynb is the path for testing the notebooks in Colab, please use this format for testing other notebooks, there are some awesome visualizations too...
-
Do we need to download the data?
- No, it is automatically downloaded, you just need to plug and play for getting the job done in Google Collaboratory.
-
Training time is taking too long?
- Yes, some of the CAPTCHAs really take long time to train, (over 10 hrs for just 10 epochs even in GPUs). It is good to have multiple GPUs when you are using this on your own machine.
-
Found a bug? or version issue?
- PRs welcome, fork it, and send a pull request!
Please feel free to raise issues and fix any existing ones. Further details can be found in our code of conduct.
- Always start your PR description with "Fixes #issue_number", if you're fixing an issue.
- Briefly mention the purpose of the PR, along with the tools/libraries you have used. It would be great if you could be version specific.
- Briefly mention what logic you used to implement the changes/upgrades.
- Provide in-code review comments on GitHub to highlight specific LOC if deemed necessary.
- Please provide snapshots if deemed necessary.
- Update readme if required.
@article{DBLP:journals/corr/abs-2006-11373,
author = {Jimut Bahan Pal},
title = {Deceiving computers in Reverse Turing Test through Deep Learning},
journal = {CoRR},
volume = {abs/2006.11373},
year = {2020},
url = {https://arxiv.org/abs/2006.11373},
archivePrefix = {arXiv},
eprint = {2006.11373},
timestamp = {Tue, 23 Jun 2020 17:57:22 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2006-11373.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}