Deep Learning Based Visual Table Recogition, Whisper for Multilingual Speech Recognition with 85+ models across various languages and 40+ new models in John Snow Labs NLU 5.1.1
We are incredibly excited to announce NLU 5.1.1 has been released with over 130+ models in 36+ languages including new models based on Whisper for multilingual automatic speech recognition and Deep Learning based Visual Table Recogition using cascade R-CNN
You can now transcribe speech to text with Whispe with 85+ models across 36 languages for Automatic Speech Recognition (ASR).
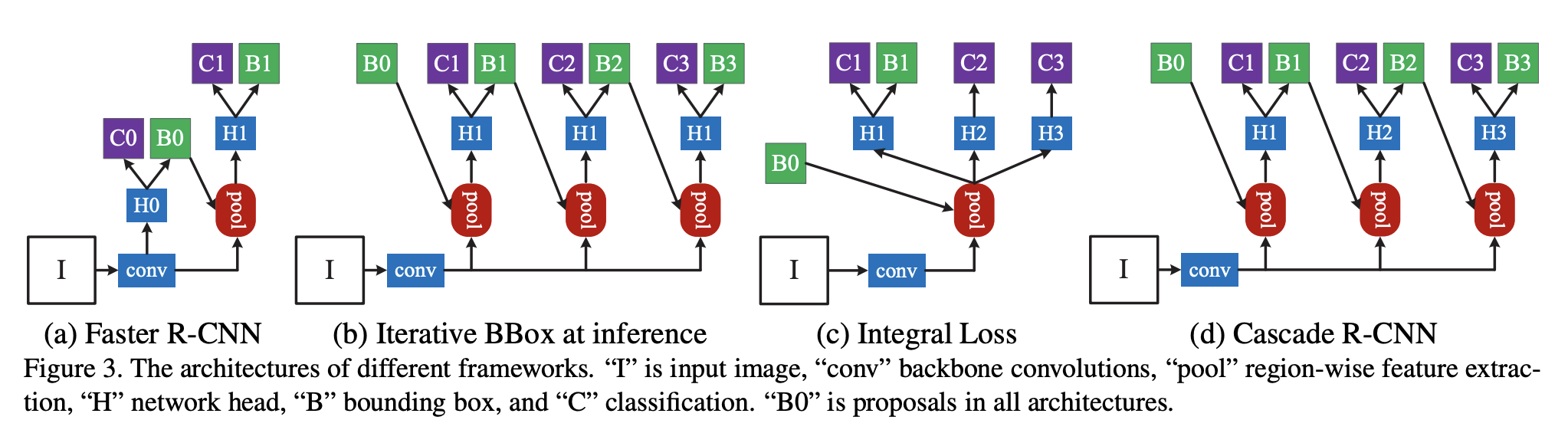
Additionally, Deep Learning based Visual Table Recogition based on an Cascade mask R-CNN HRNet that features detection of tables within images is now available in NLU 🌟.
Finally, 40+ new models for existing model classes has been added!
Deep Learning based Visual Table Recogition
You can now extract tables from images as pandas dataframe in 1 line of code, leveraging Spark OCR's ImageTableDetector, ImageTableCellDetector and ImageCellsToTextTable classes.
The ImageTableDetector is a deep-learning model designed to identify tables within images. It utilizes the CascadeTabNet architecture, which incorporates the Cascade mask Region-based Convolutional Neural Network High-Resolution Network (Cascade mask R-CNN HRNet).
The ImageTableCellDetector, on the other hand, is engineered to pinpoint cells within a table image. Its foundation is an image processing algorithm that identifies both horizontal and vertical lines.
The ImageCellsToTextTable applies Optical Character Recognition (OCR) to regions of cells within an image and returns the recognized text to the outputCol as a TableContainer structure.
It’s important to note that these annotators do not need to be invoked individually in NLU. Instead, you can simply load the image_table_cell2text_table model using the command nlp.load('image_table_cell2text_table'), and then use nlp.predict to make predictions on any document.
Powered by Spark OCR's ImageTableDetector, ImageTableCellDetector, ImageCellsToTextTable
Reference: Cascade R-CNN: High Quality Object Detection and Instance Segmentation
| language | nlu.load() reference | Spark NLP Model Reference |
|---|---|---|
| en | en.image_table_detector | General Model for Table Detection |
Whisper for CTC

Whisper Model with a language modeling head on top for Connectionist Temporal Classification (CTC). Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It transcribe in multiple languages, as well as translate from those languages into English. Whisper was trained and open-sourced that approaches human level robustness and accuracy on English speech recognition.
Powered by Spark-NLP's WhisperForCTC Annotator
Reference: OpenAI Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
Note that at the moment only Spark Versions 3.4 and up are supported.
| Language | NLU Reference | Spark NLP Reference | Annotator Class |
|---|---|---|---|
| bg | bg.speech2text.whisper.tiny_bulgarian_l | asr_whisper_tiny_bulgarian_l | WhisperForCTC |
| cs | cs.speech2text.whisper.small_czech_cv11 | asr_whisper_small_czech_cv11 | WhisperForCTC |
| da | da.speech2text.whisper.danish_small_augmented | asr_whisper_danish_small_augmented | WhisperForCTC |
| de | de.speech2text.whisper.small_allsnr | asr_whisper_small_allsnr | WhisperForCTC |
| el | el.speech2text.whisper.samoan_farsipal_e5 | asr_whisper_samoan_farsipal_e5 | WhisperForCTC |
| el | el.speech2text.whisper.small_greek | asr_whisper_small_greek | WhisperForCTC |
| el | el.speech2text.whisper.tswana_greek_modern_e1 | asr_whisper_tswana_greek_modern_e1 | WhisperForCTC |
| en | en.speech2text.whisper.small_english_model | asr_personal_whisper_small_english_model | WhisperForCTC |
| en | en.speech2text.whisper.base_bulgarian_l | asr_whisper_base_bulgarian_l | WhisperForCTC |
| en | en.speech2text.whisper.base_english | asr_whisper_base_english | WhisperForCTC |
| en | en.speech2text.whisper.base_european | asr_whisper_base_european | WhisperForCTC |
| en | en.speech2text.whisper.base_swedish | asr_whisper_base_swedish | WhisperForCTC |
| en | en.speech2text.whisper.persian_farsi | asr_whisper_persian_farsi | WhisperForCTC |
| en | en.speech2text.whisper.small_arabic_cv11 | asr_whisper_small_arabic_cv11 | WhisperForCTC |
| en | en.speech2text.whisper.small_bak | asr_whisper_small_bak | WhisperForCTC |
| en | en.speech2text.whisper.small_bengali_subhadeep | asr_whisper_small_bengali_subhadeep | WhisperForCTC |
| en | en.speech2text.whisper.small_chinese_hk | asr_whisper_small_chinese_hk | WhisperForCTC |
| en | en.speech2text.whisper.small_chinese_tw_voidful | asr_whisper_small_chinese_tw_voidful | WhisperForCTC |
| en | en.speech2text.whisper.small_english | asr_whisper_small_english | WhisperForCTC |
| en | en.speech2text.whisper.small_english_blueraccoon | asr_whisper_small_english_blueraccoon | WhisperForCTC |
| en | en.speech2text.whisper.small_german | asr_whisper_small_german | WhisperForCTC |
| en | en.speech2text.whisper.small_hungarian_cv11 | asr_whisper_small_hungarian_cv11 | WhisperForCTC |
| en | en.speech2text.whisper.small_lithuanian_serbian_v2 | asr_whisper_small_lithuanian_serbian_v2 | WhisperForCTC |
| en | en.speech2text.whisper.small_mongolian_2 | asr_whisper_small_mongolian_2 | WhisperForCTC |
| en | en.speech2text.whisper.small_mongolian_3 | asr_whisper_small_mongolian_3 | WhisperForCTC |
| en | en.speech2text.whisper.small_portuguese_yapeng | asr_whisper_small_portuguese_yapeng | WhisperForCTC |
| en | en.speech2text.whisper.small_se2 | asr_whisper_small_se2 | WhisperForCTC |
| en | en.speech2text.whisper.small_spanish_1e_6 | asr_whisper_small_spanish_1e_6 | WhisperForCTC |
| en | en.speech2text.whisper.small_swe2 | asr_whisper_small_swe2 | WhisperForCTC |
| en | en.speech2text.whisper.small_swe_davidt123 | asr_whisper_small_swe_davidt123 | WhisperForCTC |
| en | en.speech2text.whisper.small_swedish_se_afroanton | asr_whisper_small_swedish_se_afroanton | WhisperForCTC |
| en | en.speech2text.whisper.small_telugu_openslr | asr_whisper_small_telugu_openslr | WhisperForCTC |
| en | en.speech2text.whisper.small_tonga_zambia | asr_whisper_small_tonga_zambia | WhisperForCTC |
| en | en.speech2text.whisper.small_urdu_1000_64_1e_05_pretrain_arabic | asr_whisper_small_urdu_1000_64_1e_05_pretrain_arabic | WhisperForCTC |
| en | en.speech2text.whisper.testrun1 | asr_whisper_testrun1 | WhisperForCTC |
| en | en.speech2text.whisper.tiny_english | asr_whisper_tiny_english | WhisperForCTC |
| en | en.speech2text.whisper.tiny_european | asr_whisper_tiny_european | WhisperForCTC |
| en | en.speech2text.whisper.tiny_german | asr_whisper_tiny_german | WhisperForCTC |
| en | en.speech2text.whisper.tiny_italian_local | asr_whisper_tiny_italian_local | WhisperForCTC |
| en | en.speech2text.whisper.tiny_pashto | asr_whisper_tiny_pashto | WhisperForCTC |
| en | en.speech2text.whisper.tiny_tgl | asr_whisper_tiny_tgl | WhisperForCTC |
| es | es.speech2text.whisper.small_spanish_ari | asr_whisper_small_spanish_ari | WhisperForCTC |
| es | es.speech2text.whisper.tiny_spanish_arpagon | asr_whisper_tiny_spanish_arpagon | WhisperForCTC |
| fi | fi.speech2text.whisper.small_finnish_15k_samples | asr_whisper_small_finnish_15k_samples | WhisperForCTC |
| fi | fi.speech2text.whisper.small_finnish_sgangireddy | asr_whisper_small_finnish_sgangireddy | WhisperForCTC |
| fr | fr.speech2text.whisper.small_defined_dot_ai_qc_french_combined_dataset_normalized | asr_whisper_small_defined_dot_ai_qc_french_combined_dataset_normalized | WhisperForCTC |
| hi | hi.speech2text.whisper.small_french_yocel1 | asr_whisper_small_french_yocel1 | WhisperForCTC |
| hi | hi.speech2text.whisper.small_hindi_norwegian_tensorboard | asr_whisper_small_hindi_norwegian_tensorboard | WhisperForCTC |
| hi | hi.speech2text.whisper.small_hindi_shripadbhat | asr_whisper_small_hindi_shripadbhat | WhisperForCTC |
| hi | hi.speech2text.whisper.small_hindi_xinhuang | asr_whisper_small_hindi_xinhuang | WhisperForCTC |
| hy | hy.speech2text.whisper.small_armenian | asr_whisper_small_armenian | WhisperForCTC |
| it | it.speech2text.whisper.small_italian_3 | asr_whisper_small_italian_3 | WhisperForCTC |
| it | it.speech2text.whisper.tiny_italian_1 | asr_whisper_tiny_italian_1 | WhisperForCTC |
| it | it.speech2text.whisper.tiny_italian_2 | asr_whisper_tiny_italian_2 | WhisperForCTC |
| ja | ja.speech2text.whisper.small_japanese_jakeyoo | asr_whisper_small_japanese_jakeyoo | WhisperForCTC |
| ja | ja.speech2text.whisper.small_japanese_vumichien | asr_whisper_small_japanese_vumichien | WhisperForCTC |
| kn | kn.speech2text.whisper.kannada_base | asr_whisper_kannada_base | WhisperForCTC |
| kn | kn.speech2text.whisper.kannada_small | asr_whisper_kannada_small | WhisperForCTC |
| ko | ko.speech2text.whisper.small_korean_fl | asr_whisper_small_korean_fl | WhisperForCTC |
| lt | lt.speech2text.whisper.lithuanian_finetune | asr_whisper_lithuanian_finetune | WhisperForCTC |
| lt | lt.speech2text.whisper.small_lithuanian_deividasm | asr_whisper_small_lithuanian_deividasm | WhisperForCTC |
| ml | ml.speech2text.whisper.malayalam_first_model | asr_whisper_malayalam_first_model | WhisperForCTC |
| mn | mn.speech2text.whisper.small_mongolian_1 | asr_whisper_small_mongolian_1 | WhisperForCTC |
| ne | ne.speech2text.whisper.small_nepali_np | asr_whisper_small_nepali_np | WhisperForCTC |
| nl | nl.speech2text.whisper.small_dutch | asr_whisper_small_dutch | WhisperForCTC |
| no | no.speech2text.whisper.small_nob | asr_whisper_small_nob | WhisperForCTC |
| pa | pa.speech2text.whisper.small_punjabi_eastern | asr_whisper_small_punjabi_eastern | WhisperForCTC |
| pl | pl.speech2text.whisper.small_polish_aspik101 | asr_whisper_small_polish_aspik101 | WhisperForCTC |
| pl | pl.speech2text.whisper.tiny_polish | asr_whisper_tiny_polish | WhisperForCTC |
| ps | ps.speech2text.whisper.small_pashto_ihanif | asr_whisper_small_pashto_ihanif | WhisperForCTC |
| sv | sv.speech2text.whisper.small_swedish_english | asr_whisper_small_swedish_english | WhisperForCTC |
| sv | sv.speech2text.whisper.small_swedish_test_3000 | asr_whisper_small_swedish_test_3000 | WhisperForCTC |
| sv | sv.speech2text.whisper.small_swedish_torileatherman | asr_whisper_small_swedish_torileatherman | WhisperForCTC |
| sw | sw.speech2text.whisper.small_swahili_pplantinga | asr_whisper_small_swahili_pplantinga | WhisperForCTC |
| ta | ta.speech2text.whisper.tiny_tamil_example | asr_whisper_tiny_tamil_example | WhisperForCTC |
| te | te.speech2text.whisper.small_telugu_146h | asr_whisper_small_telugu_146h | WhisperForCTC |
| te | te.speech2text.whisper.telugu_tiny | asr_whisper_telugu_tiny | WhisperForCTC |
| th | th.speech2text.whisper.small_thai_napatswift | asr_whisper_small_thai_napatswift | WhisperForCTC |
| tt | tt.speech2text.whisper.small_tatar | asr_whisper_small_tatar | WhisperForCTC |
| uk | uk.speech2text.whisper.small_ukrainian | asr_whisper_small_ukrainian | WhisperForCTC |
| uz | uz.speech2text.whisper.small_uzbek | asr_whisper_small_uzbek | WhisperForCTC |
| vi | vi.speech2text.whisper.small_vietnamese_tuananh7198 | asr_whisper_small_vietnamese_tuananh7198 | WhisperForCTC |
| xx | xx.speech2text.whisper.base | asr_whisper_base | WhisperForCTC |
| xx | xx.speech2text.whisper.base_bengali_trans | asr_whisper_base_bengali_trans | WhisperForCTC |
| xx | xx.speech2text.whisper.small | asr_whisper_small | WhisperForCTC |
| xx | xx.speech2text.whisper.tiny | asr_whisper_tiny | WhisperForCTC |
| xx | xx.speech2text.whisper.tiny_opt | asr_whisper_tiny_opt | WhisperForCTC |
| zh | zh.speech2text.whisper.small_chinese | asr_whisper_small_chinese | WhisperForCTC |
| zh | zh.speech2text.whisper.small_chinesebasetw | asr_whisper_small_chinesebasetw | WhisperForCTC |
New Models
| Language | NLU Reference | Spark NLP Reference | Annotator Class |
|---|---|---|---|
| en | en.assert.sdoh_wip | assertion_sdoh_wip | AssertionDLModel |
| en | en.assert.vop_clinical_large | assertion_vop_clinical_large | AssertionDLModel |
| ar | ar.answer_question.bert_qa | bert_qa_arap | BertForQuestionAnswering |
| ar | ar.ner.bert.by_boda | bert_token_classifier_aner | BertForTokenClassification |
| zh | zh.ner.bert.base.multi_by_ckiplab | bert_token_classifier_base_chinese_ner | BertForTokenClassification |
| tr | tr.ner.bert.cased.by_akdeniz27 | bert_token_classifier_base_turkish_cased_ner | BertForTokenClassification |
| hu | hu.ner.bert.by_nytk | bert_token_classifier_named_entity_recognition_nerkor_hu_hungarian | BertForTokenClassification |
| xx | xx.answer_question.distil_bert.cased_squadv2 | distilbert_qa_base_cased_squadv2 | DistilBertForQuestionAnswering |
| en | en.classify.bert_sequence.vop_drug_side_effect | bert_sequence_classifier_vop_drug_side_effect | MedicalBertForSequenceClassification |
| en | en.classify.bert_sequence.vop_hcp_consult | bert_sequence_classifier_vop_hcp_consult | MedicalBertForSequenceClassification |
| en | en.classify.bert_sequence.vop_self_report | bert_sequence_classifier_vop_self_report | MedicalBertForSequenceClassification |
| en | en.classify.bert_sequence.vop_side_effect | bert_sequence_classifier_vop_side_effect | MedicalBertForSequenceClassification |
| en | en.classify.bert_sequence.vop_sound_medical | bert_sequence_classifier_vop_sound_medical | MedicalBertForSequenceClassification |
| en | en.med_ner.sdoh | ner_sdoh | MedicalNerModel |
| en | en.med_ner.sdoh_access_to_healthcare | ner_sdoh_access_to_healthcare | MedicalNerModel |
| en | en.med_ner.sdoh_community_condition | ner_sdoh_community_condition | MedicalNerModel |
| en | en.med_ner.sdoh_demographics | ner_sdoh_demographics | MedicalNerModel |
| en | en.med_ner.sdoh_health_behaviours_problems | ner_sdoh_health_behaviours_problems | MedicalNerModel |
| en | en.med_ner.sdoh_income_social_status | ner_sdoh_income_social_status | MedicalNerModel |
| en | en.med_ner.sdoh_social_environment | ner_sdoh_social_environment | MedicalNerModel |
| en | en.med_ner.sdoh_substance_usage | ner_sdoh_substance_usage | MedicalNerModel |
| en | en.med_ner.vop | ner_vop | MedicalNerModel |
| en | en.med_ner.vop_emb_clinical_large | ner_vop_emb_clinical_large | MedicalNerModel |
| en | en.summarize.clinical_laymen_onnx | summarizer_clinical_laymen_onnx | MedicalSummarizer |
| en | en.classify.hoc | multiclassifierdl_hoc | MultiClassifierDLModel |
| en | en.med_ner.chemd_clinical.pipeline | ner_chemd_clinical_pipeline | PipelineModel |
| en | en.med_ner.jsl_langtest.pipeline | ner_jsl_langtest_pipeline | PipelineModel |
| en | en.med_ner.living_species.pipeline | ner_living_species_pipeline | PipelineModel |
| en | en.med_ner.oncology_posology_langtest.pipeline | ner_oncology_posology_langtest_pipeline | PipelineModel |
| en | en.med_ner.profiling_oncology | ner_profiling_oncology | PipelineModel |
| en | en.med_ner.profiling_sdoh | ner_profiling_sdoh | PipelineModel |
| en | en.med_ner.profiling_vop | ner_profiling_vop | PipelineModel |
| en | en.med_ner.sdoh_langtest.pipeline | ner_sdoh_langtest_pipeline | PipelineModel |
| en | en.med_ner.supplement_clinical.pipeline | ner_supplement_clinical_pipeline | PipelineModel |
| en | en.summarize.clinical_guidelines_large.pipeline | summarizer_clinical_guidelines_large_pipeline | PipelineModel |
| en | en.summarize.clinical_jsl_augmented.pipeline | summarizer_clinical_jsl_augmented_pipeline | PipelineModel |
| en | en.summarize.clinical_questions.pipeline | summarizer_clinical_questions_pipeline | PipelineModel |
| en | en.summarize.generic_jsl.pipeline | summarizer_generic_jsl_pipeline | PipelineModel |
| en | en.summarize.radiology.pipeline | summarizer_radiology_pipeline | PipelineModel |
| en | en.embed.glove.clinical_large | embeddings_clinical_large | WordEmbeddingsModel |
Minor Features
- New feature has been incorporated into the Light Pipeline. This feature allows users to enable or disable the usage of the Light Pipeline by setting
pipe.is_light_pipe_incompatible=True.
📖 Additional NLU resources
- 140+ NLU Tutorials
- Streamlit visualizations docs
- The complete list of all 20000+ models & pipelines in 300+ languages is available on Models Hub
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
Installation
#PyPI
pip install nlu pyspark