Support for Speech2Text, Images-Classification, Tabular Data, Zero-Shot-NER, via Wav2Vec2, Tapas, VIT , 4000+ New Models, 90+ Languages, in John Snow Labs NLU 4.2.0
Support for Speech2Text, Images-Classification, Tabular Data, Zero-Shot-NER, via Wav2Vec2, Tapas, VIT , 4000+ New Models, 90+ Languages, in John Snow Labs NLU 4.2.0
We are incredibly excited to announce NLU 4.2.0 has been released with new 4000+ models in 90+ languages and support for new 8 Deep Learning Architectures.
4 new tasks are included for the very first time,
Zero-Shot-NER, Automatic Speech Recognition, Image Classification and Table Question Answering powered
by Wav2Vec 2.0, HuBERT, TAPAS, VIT, SWIN, Zero-Shot-NER.
Additionally, CamemBERT based architectures are available for Sequence and Token Classification powered by Spark-NLPs
CamemBertForSequenceClassification and CamemBertForTokenClassification
Automatic Speech Recognition (ASR)
Demo Notebook
Wav2Vec 2.0 and HuBERT enable ASR for the very first time in NLU.
Wav2Vec2 is a transformer model for speech recognition that uses unsupervised pre-training on large amounts of unlabeled speech data to improve the accuracy of automatic speech recognition (ASR) systems. It is based on a self-supervised learning approach that learns to predict masked portions of speech signal, and has shown promising results in reducing the amount of labeled training data required for ASR tasks.
These Models are powered by Spark-NLP's Wav2Vec2ForCTC Annotator

HuBERT models match or surpass the SOTA approaches for speech representation learning for speech recognition, generation, and compression. The Hidden-Unit BERT (HuBERT) approach was proposed for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss.
These Models is powered by Spark-NLP's HubertForCTC Annotator

Usage
You just need an audio-file on disk and pass the path to it or a folder of audio-files.
import nlu
# Let's download an audio file
!wget https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/audio/samples/wavs/ngm_12484_01067234848.wav
# Let's listen to it
from IPython.display import Audio
FILE_PATH = "ngm_12484_01067234848.wav"
asr_df = nlu.load('en.speech2text.wav2vec2.v2_base_960h').predict('ngm_12484_01067234848.wav')
asr_df| text |
|---|
| PEOPLE WHO DIED WHILE LIVING IN OTHER PLACES |
To test out HuBERT you just need to update the parameter for load()
asr_df = nlu.load('en.speech2text.hubert').predict('ngm_12484_01067234848.wav')
asr_dfImage Classification
For the first time ever NLU introduces state-of-the-art image classifiers based on
VIT and Swin giving you access to hundreds of image classifiers for various domains.
Inspired by the Transformer scaling successes in NLP, the researchers experimented with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, images are split into patches and the sequence of linear embeddings of these patches were provided as an input to a Transformer. Image patches were actually treated the same way as tokens (words) in an NLP application. Image classification models were trained in supervised fashion.
You can check Scale Vision Transformers (ViT) Beyond Hugging Face article to learn deeper how ViT works and how it is implemeted in Spark NLP.
This is Powerd by Spark-NLP's VitForImageClassification Annotator
Swin is a hierarchical Transformer whose representation is computed with Shifted windows.
The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection.
This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks
This is powerd by Spark-NLP's Swin For Image Classification
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.

Usage:
# Download an image
os.system('wget https://raw.githubusercontent.com/JohnSnowLabs/nlu/release/4.2.0/tests/datasets/ocr/vit/ox.jpg')
# Load VIT model and predict on image file
vit = nlu.load('en.classify_image.base_patch16_224').predict('ox.jpg')Lets download a folder of images and predict on it
!wget -q https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/images/images.zip
import shutil
shutil.unpack_archive("images.zip", "images", "zip")
! ls /content/images/images/Once we have image data its easy to label it, we just pass the folder with images to nlu.predict()
and NLU will return a pandas DF with one row per image detected
nlu.load('en.classify_image.base_patch16_224').predict('/content/images/images')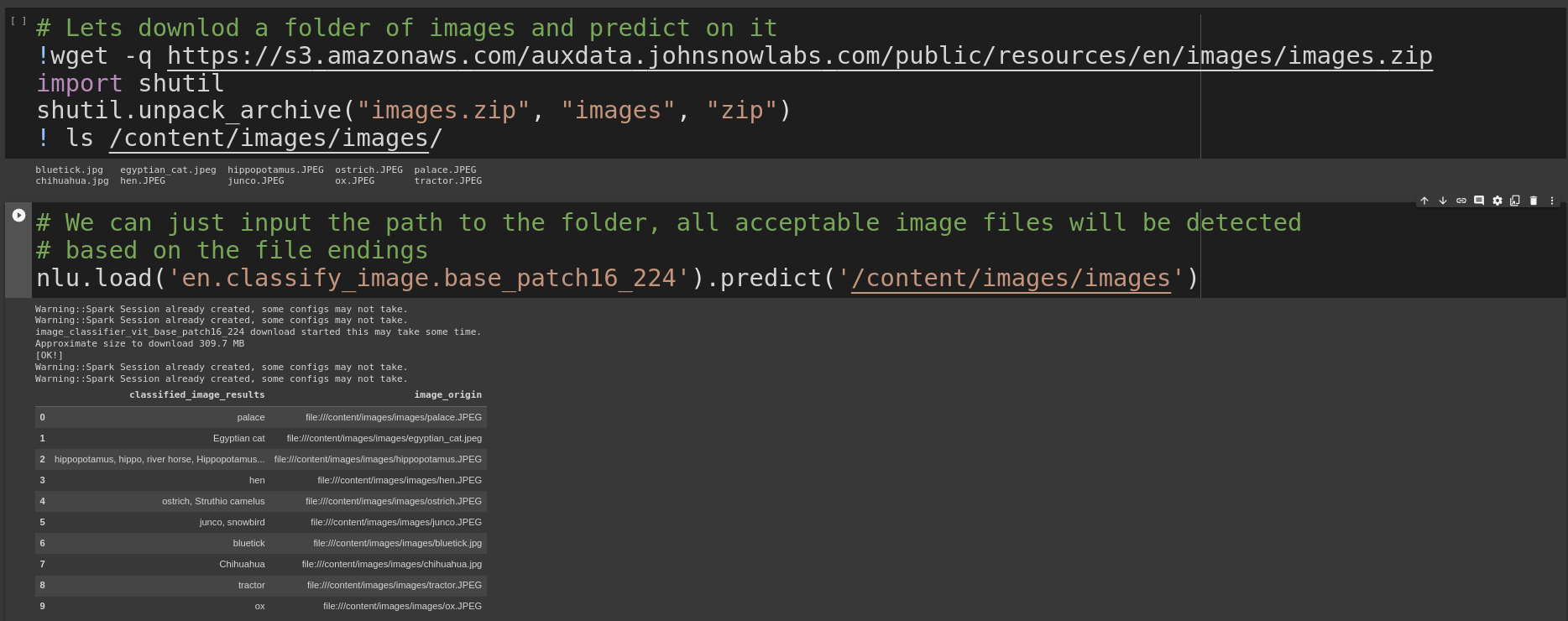
To use SWIN we just update the parameter to load()
load('en.classify_image.swin.tiny').predict('/content/images/images')Visual Table Question Answering
TapasForQuestionAnswering can load TAPAS Models with a cell selection head and optional aggregation head on top for question-answering tasks on tables (linear layers on top of the hidden-states output to compute logits and optional logits_aggregation), e.g. for SQA, WTQ or WikiSQL-supervised tasks. TAPAS is a BERT-based model specifically designed (and pre-trained) for answering questions about tabular data.
Powered by TAPAS: Weakly Supervised Table Parsing via Pre-training

Usage:
First we need a pandas dataframe on for which we want to ask questions. The so called "context"
import pandas as pd
context_df = pd.DataFrame({
'name':['Donald Trump','Elon Musk'],
'money': ['$100,000,000','$20,000,000,000,000'],
'married': ['yes','no'],
'age' : ['75','55'] })
context_dfThen we create an array of questions
questions = [
"Who earns less than 200,000,000?",
"Who earns more than 200,000,000?",
"Who earns 100,000,000?",
"How much money has Donald Trump?",
"Who is the youngest?",
]
questionsNow Combine the data, pass it to NLU and get answers for your questions
import nlu
# Now we combine both to a tuple and we are done! We can now pass this to the .predict() method
tapas_data = (context_df, questions)
# Lets load a TAPAS QA model and predict on (context,question).
# It will give us an aswer for every question in the questions array, based on the context in context_df
answers = nlu.load('en.answer_question.tapas.wtq.large_finetuned').predict(tapas_data)
answers| sentence | tapas_qa_UNIQUE_aggregation | tapas_qa_UNIQUE_answer | tapas_qa_UNIQUE_cell_positions | tapas_qa_UNIQUE_cell_scores | tapas_qa_UNIQUE_origin_question |
|---|---|---|---|---|---|
| Who earns less than 200,000,000? | NONE | Donald Trump | [0, 0] | 1 | Who earns less than 200,000,000? |
| Who earns more than 200,000,000? | NONE | Elon Musk | [0, 1] | 1 | Who earns more than 200,000,000? |
| Who earns 100,000,000? | NONE | Donald Trump | [0, 0] | 1 | Who earns 100,000,000? |
| How much money has Donald Trump? | SUM | SUM($100,000,000) | [1, 0] | 1 | How much money has Donald Trump? |
| Who is the youngest? | NONE | Elon Musk | [0, 1] | 1 | Who is the youngest? |
Zero-Shot NER
Demo Notebook
Based on John Snow Labs Enterprise-NLP ZeroShotNerModel
This architecture is based on RoBertaForQuestionAnswering.
Zero shot models excel at generalization, meaning that the model can accurately predict entities in very different data sets without the need to fine tune the model or train from scratch for each different domain.
Even though a model trained to solve a specific problem can achieve better accuracy than a zero-shot model in this specific task,
it probably won’t be be useful in a different task.
That is where zero-shot models shows its usefulness by being able to achieve good results in various domains.
Usage:
We just need to load the zero-shot NER model and configure a set of entity definitions.
import nlu
# load zero-shot ner model
enterprise_zero_shot_ner = nlu.load('en.zero_shot.ner_roberta')
# Configure entity definitions
enterprise_zero_shot_ner['zero_shot_ner'].setEntityDefinitions(
{
"PROBLEM": [
"What is the disease?",
"What is his symptom?",
"What is her disease?",
"What is his disease?",
"What is the problem?",
"What does a patient suffer",
"What was the reason that the patient is admitted to the clinic?",
],
"DRUG": [
"Which drug?",
"Which is the drug?",
"What is the drug?",
"Which drug does he use?",
"Which drug does she use?",
"Which drug do I use?",
"Which drug is prescribed for a symptom?",
],
"ADMISSION_DATE": ["When did patient admitted to a clinic?"],
"PATIENT_AGE": [
"How old is the patient?",
"What is the gae of the patient?",
],
}
)Then we can already use this pipeline to predict labels
# Predict entities
df = enterprise_zero_shot_ner.predict(
[
"The doctor pescribed Majezik for my severe headache.",
"The patient was admitted to the hospital for his colon cancer.",
"27 years old patient was admitted to clinic on Sep 1st by Dr."+
"X for a right-sided pleural effusion for thoracentesis.",
]
)
df| document | entities_zero_shot | entities_zero_shot_class | entities_zero_shot_confidence | entities_zero_shot_origin_chunk | entities_zero_shot_origin_sentence |
|---|---|---|---|---|---|
| The doctor pescribed Majezik for my severe headache. | Majezik | DRUG | 0.646716 | 0 | 0 |
| The doctor pescribed Majezik for my severe headache. | severe headache | PROBLEM | 0.552635 | 1 | 0 |
| The patient was admitted to the hospital for his colon cancer. | colon cancer | PROBLEM | 0.88985 | 0 | 0 |
| 27 years old patient was admitted to clinic on Sep 1st by Dr. X for a right-sided pleural effusion for thoracentesis. | 27 years old | PATIENT_AGE | 0.694308 | 0 | 0 |
| 27 years old patient was admitted to clinic on Sep 1st by Dr. X for a right-sided pleural effusion for thoracentesis. | Sep 1st | ADMISSION_DATE | 0.956461 | 1 | 0 |
| 27 years old patient was admitted to clinic on Sep 1st by Dr. X for a right-sided pleural effusion for thoracentesis. | a right-sided pleural effusion for thoracentesis | PROBLEM | 0.500266 | 2 | 0 |
New Notebooks
- Image Classification with VIT and Swin
- Zero-Shot-NER
- Table Question Answering with TAPAS
- Automatic Speech Recognition with Wav2Vec2 and HuBERT
New Models Overview
Supported Languages are:
ab, am, ar, ba, bem, bg, bn, ca, co, cs, da, de, dv, el, en, es, et, eu, fa, fi, fon, fr, fy, ga, gam, gl, gu, ha, he, hi, hr, hu, id, ig, is, it, ja, jv, kin, kn, ko, kr, ku, ky, la, lg, lo, lt, lu, luo, lv, lwt, ml, mn, mr, ms, mt, nb, nl, no, pcm, pl, pt, ro, ru, rw, sg, si, sk, sl, sq, st, su, sv, sw, swa, ta, te, th, ti, tl, tn, tr, tt, tw, uk, unk, ur, uz, vi, wo, xx, yo, yue, zh, zu
Automatic Speech Recognition Models Overview
Image Classification Models Overview
Install NLU
pip install nlu pysparkAdditional NLU resources
- 140+ NLU Tutorials
- NLU in Action
- Streamlit visualizations docs
- The complete list of all 4000+ models & pipelines in 200+ languages is available on Models Hub.
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!