

Spring Cloud Sleuth provides Spring Boot auto-configuration for distributed tracing. Underneath, Spring Cloud Sleuth is a layer over a tracer library named Brave.
Sleuth configures everything you need to get started. This includes where trace data (spans) are reported to, how many traces to keep (sampling), if remote fields (baggage) are sent, and which libraries are traced.
Add sleuth to the classpath of a Spring Boot application (see “Adding Sleuth to your Project” for Maven and Gradle examples), and you will see trace IDs in logs.
For example, consider the following HTTP handler:
@RestController
public class DemoController {
private static Logger log = LoggerFactory.getLogger(DemoController.class);
@RequestMapping("/")
public String home() {
log.info("Handling home");
...
return "Hello World";
}
}If you add that handler to a controller, you can see the calls to home()
being traced in the logs as well in Zipkin, if configured.
|
Note
|
Instead of logging the request in the handler explicitly, you
could set logging.level.org.springframework.web.servlet.DispatcherServlet=DEBUG.
|
|
Note
|
Set spring.application.name=myService (for instance) to see the service
name as well as the trace and span IDs.
|
Spring Cloud Sleuth provides Spring Boot auto-configuration for distributed tracing. Underneath, Spring Cloud Sleuth is a layer over a Tracer library named Brave.
Sleuth configures everything you need to get started. This includes where trace data (spans) are reported to, how many traces to keep (sampling), if remote fields (baggage) are sent, and which libraries are traced.
We maintain an example app where two Spring Boot services collaborate on an HTTP request. Sleuth configures these apps, so that timing of these requests are recorded into Zipkin, a distributed tracing system. Tracing UIs visualize latency, such as time in one service vs waiting for other services.
Here’s an example of what it looks like:

The source repository of this example includes demonstrations of many things, including WebFlux and messaging. Most features require only a property or dependency change to work. These snippets showcase the value of Spring Cloud Sleuth: Through auto-configuration, Sleuth make getting started with distributed tracing easy!
To keep things simple, the same example is used throughout documentation using basic HTTP communication.
Sleuth sets up instrumentation not only to track timing, but also to catch
errors so that they can be analyzed or correlated with logs. This works the
same way regardless of if the error came from a common instrumented library,
such as RestTemplate, or your own code annotated with @NewSpan or similar.
Below, we’ll use the word Zipkin to describe the tracing system, and include Zipkin screenshots. However, most services accepting Zipkin format have similar base features. Sleuth can also be configured to send data in other formats, something detailed later.
Without distributed tracing, it can be difficult to understand the impact of a an exception. For example, it can be hard to know if a specific request caused the caller to fail or not.
Zipkin reduces time in triage by contextualizing errors and delays.
Requests colored red in the search screen failed:

If you then click on one of the traces, you can understand if the failure happened before the request hit another service or not:

For example, the above error happened in the "backend" service, and caused the "frontend" service to fail.
Sleuth configures the logging context with variables including the service name
(%{spring.zipkin.service.name}) and the trace ID (%{traceId}). These help
you connect logs with distributed traces and allow you choice in what tools you
use to troubleshoot your services.
Once you find any log with an error, you can look for the trace ID in the message. Paste that into Zipkin to visualize the entire trace, regardless of how many services the first request ended up hitting.
backend.log: 2020-04-09 17:45:40.516 ERROR [backend,5e8eeec48b08e26882aba313eb08f0a4,dcc1df555b5777b3,true] 97203 --- [nio-9000-exec-1] o.s.c.s.i.web.ExceptionLoggingFilter : Uncaught exception thrown
frontend.log:2020-04-09 17:45:40.574 ERROR [frontend,5e8eeec48b08e26882aba313eb08f0a4,82aba313eb08f0a4,true] 97192 --- [nio-8081-exec-2] o.s.c.s.i.web.ExceptionLoggingFilter : Uncaught exception thrownAbove, you’ll notice the trace ID is 5e8eeec48b08e26882aba313eb08f0a4, for
example. This log configuration was automatically setup by Sleuth.
When you consider distributed tracing tracks requests, it makes sense that trace data can paint a picture of your architecture.
Zipkin includes a tool to build service dependency diagrams from traces, including the count of calls and how many errors exist.
The example application will make a simple diagram like this, but your real environment diagram may be more complex.
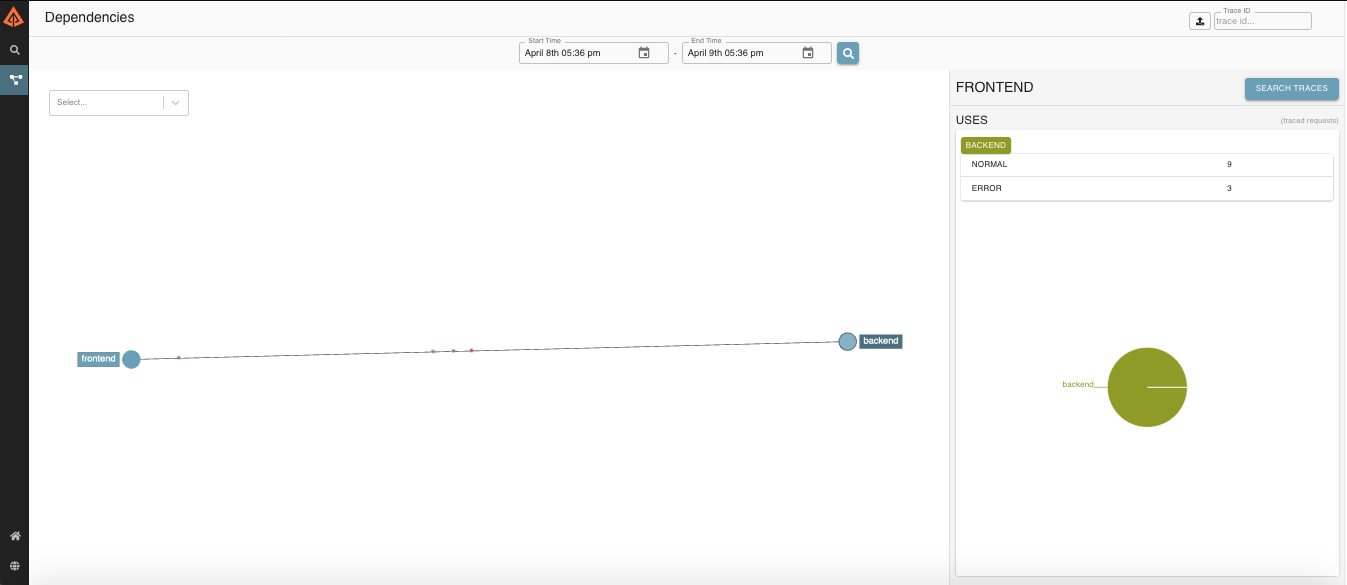
Note: Production environments will generate a lot of data. You will likely need to run a separate service to aggregate the dependency graph. You can learn more here.
Distributed tracing works by propagating fields inside and across services that connect the trace together: traceId and spanId notably. The context that holds these fields can optionally push other fields that need to be consistent regardless of many services are touched. The simple name for these extra fields is "Baggage".
Sleuth allows you to define which baggage are permitted to exist in the trace context, including what header names are used.
The following example shows setting baggage values:
Span initialSpan = this.tracer.nextSpan().name("span").start();
BUSINESS_PROCESS.updateValue(initialSpan.context(), "ALM");
COUNTRY_CODE.updateValue(initialSpan.context(), "FO");|
Important
|
There is currently no limitation of the count or size of baggage items. Keep in mind that too many can decrease system throughput or increase RPC latency. In extreme cases, too much baggage can crash the application, due to exceeding transport-level message or header capacity. |
Like trace IDs, Baggage is attached to messages or requests, usually as headers. Tags are key value pairs sent in a Span to Zipkin. Baggage values are not added spans by default, which means you can’t search based on Baggage unless you opt-in.
To make baggage also tags, use the property spring.sleuth.baggage.tag-fields
like so:
spring:
sleuth:
baggage:
foo: bar
remoteFields:
- country-code
- x-vcap-request-id
tagFields:
- country-codeThis section addresses how to add Sleuth to your project with either Maven or Gradle.
|
Important
|
To ensure that your application name is properly displayed in Zipkin, set the spring.application.name property in bootstrap.yml.
|
If you want both Sleuth and Zipkin, add the spring-cloud-starter-zipkin dependency.
The following example shows how to do so for Maven:
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin.
The following example shows how to do so for Gradle:
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin.
If you want to use RabbitMQ or Kafka instead of HTTP, add the spring-rabbit or spring-kafka dependency.
The default destination name is zipkin.
If using Kafka, you must set the property spring.zipkin.sender.type property accordingly:
spring.zipkin.sender.type: kafka|
Caution
|
spring-cloud-sleuth-stream is deprecated and incompatible with these destinations.
|
If you want Sleuth over RabbitMQ, add the spring-cloud-starter-zipkin and spring-rabbit
dependencies.
The following example shows how to do so for Gradle:
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin. That way, all nested dependencies get downloaded. -
To automatically configure RabbitMQ, add the
spring-rabbitdependency.
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin" (2)
compile "org.springframework.amqp:spring-rabbit" (3)
}-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-zipkin. That way, all nested dependencies get downloaded. -
To automatically configure RabbitMQ, add the
spring-rabbitdependency.
Spring Cloud Sleuth supports sending traces to multiple tracing systems as of version 2.1.0.
In order to get this to work, every tracing system needs to have a Reporter<Span> and Sender.
If you want to override the provided beans you need to give them a specific name.
To do this you can use respectively ZipkinAutoConfiguration.REPORTER_BEAN_NAME and ZipkinAutoConfiguration.SENDER_BEAN_NAME.
@Configuration
protected static class MyConfig {
@Bean(ZipkinAutoConfiguration.REPORTER_BEAN_NAME)
Reporter<zipkin2.Span> myReporter() {
return AsyncReporter.create(mySender());
}
@Bean(ZipkinAutoConfiguration.SENDER_BEAN_NAME)
MySender mySender() {
return new MySender();
}
static class MySender extends Sender {
private boolean spanSent = false;
boolean isSpanSent() {
return this.spanSent;
}
@Override
public Encoding encoding() {
return Encoding.JSON;
}
@Override
public int messageMaxBytes() {
return Integer.MAX_VALUE;
}
@Override
public int messageSizeInBytes(List<byte[]> encodedSpans) {
return encoding().listSizeInBytes(encodedSpans);
}
@Override
public Call<Void> sendSpans(List<byte[]> encodedSpans) {
this.spanSent = true;
return Call.create(null);
}
}
}If you want to use only Spring Cloud Sleuth without the Zipkin integration, add the spring-cloud-starter-sleuth module to your project.
The following example shows how to add Sleuth with Maven:
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-sleuth.
The following example shows how to add Sleuth with Gradle:
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}-
We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself.
-
Add the dependency to
spring-cloud-starter-sleuth.
To build the source you will need to install JDK 1.7.
Spring Cloud uses Maven for most build-related activities, and you should be able to get off the ground quite quickly by cloning the project you are interested in and typing
$ ./mvnw install
|
Note
|
You can also install Maven (>=3.3.3) yourself and run the mvn command
in place of ./mvnw in the examples below. If you do that you also
might need to add -P spring if your local Maven settings do not
contain repository declarations for spring pre-release artifacts.
|
|
Note
|
Be aware that you might need to increase the amount of memory
available to Maven by setting a MAVEN_OPTS environment variable with
a value like -Xmx512m -XX:MaxPermSize=128m. We try to cover this in
the .mvn configuration, so if you find you have to do it to make a
build succeed, please raise a ticket to get the settings added to
source control.
|
For hints on how to build the project look in .travis.yml if there
is one. There should be a "script" and maybe "install" command. Also
look at the "services" section to see if any services need to be
running locally (e.g. mongo or rabbit). Ignore the git-related bits
that you might find in "before_install" since they’re related to setting git
credentials and you already have those.
The projects that require middleware generally include a
docker-compose.yml, so consider using
Docker Compose to run the middeware servers
in Docker containers. See the README in the
scripts demo
repository for specific instructions about the common cases of mongo,
rabbit and redis.
|
Note
|
If all else fails, build with the command from .travis.yml (usually
./mvnw install).
|
The spring-cloud-build module has a "docs" profile, and if you switch
that on it will try to build asciidoc sources from
src/main/asciidoc. As part of that process it will look for a
README.adoc and process it by loading all the includes, but not
parsing or rendering it, just copying it to ${main.basedir}
(defaults to ${basedir}, i.e. the root of the project). If there are
any changes in the README it will then show up after a Maven build as
a modified file in the correct place. Just commit it and push the change.
If you don’t have an IDE preference we would recommend that you use Spring Tools Suite or Eclipse when working with the code. We use the m2eclipse eclipse plugin for maven support. Other IDEs and tools should also work without issue as long as they use Maven 3.3.3 or better.
Spring Cloud projects require the 'spring' Maven profile to be activated to resolve the spring milestone and snapshot repositories. Use your preferred IDE to set this profile to be active, or you may experience build errors.
We recommend the m2eclipse eclipse plugin when working with eclipse. If you don’t already have m2eclipse installed it is available from the "eclipse marketplace".
|
Note
|
Older versions of m2e do not support Maven 3.3, so once the
projects are imported into Eclipse you will also need to tell
m2eclipse to use the right profile for the projects. If you
see many different errors related to the POMs in the projects, check
that you have an up to date installation. If you can’t upgrade m2e,
add the "spring" profile to your settings.xml. Alternatively you can
copy the repository settings from the "spring" profile of the parent
pom into your settings.xml.
|
If you prefer not to use m2eclipse you can generate eclipse project metadata using the following command:
$ ./mvnw eclipse:eclipse
The generated eclipse projects can be imported by selecting import existing projects
from the file menu.
|
Important
|
Spring Cloud Sleuth uses two different versions of language level. Java 1.7 is used for main sources, and
Java 1.8 is used for tests. When importing your project to an IDE, you should activate the ide Maven profile to turn on
Java 1.8 for both main and test sources. You MUST NOT use Java 1.8 features in the main sources. If you do
so, your app breaks during the Maven build.
|
Spring Cloud is released under the non-restrictive Apache 2.0 license, and follows a very standard Github development process, using Github tracker for issues and merging pull requests into master. If you want to contribute even something trivial please do not hesitate, but follow the guidelines below.
Before we accept a non-trivial patch or pull request we will need you to sign the Contributor License Agreement. Signing the contributor’s agreement does not grant anyone commit rights to the main repository, but it does mean that we can accept your contributions, and you will get an author credit if we do. Active contributors might be asked to join the core team, and given the ability to merge pull requests.
This project adheres to the Contributor Covenant code of conduct. By participating, you are expected to uphold this code. Please report unacceptable behavior to [email protected].
None of these is essential for a pull request, but they will all help. They can also be added after the original pull request but before a merge.
-
Use the Spring Framework code format conventions. If you use Eclipse you can import formatter settings using the
eclipse-code-formatter.xmlfile from the Spring Cloud Build project. If using IntelliJ, you can use the Eclipse Code Formatter Plugin to import the same file. -
Make sure all new
.javafiles to have a simple Javadoc class comment with at least an@authortag identifying you, and preferably at least a paragraph on what the class is for. -
Add the ASF license header comment to all new
.javafiles (copy from existing files in the project) -
Add yourself as an
@authorto the .java files that you modify substantially (more than cosmetic changes). -
Add some Javadocs and, if you change the namespace, some XSD doc elements.
-
A few unit tests would help a lot as well — someone has to do it.
-
If no-one else is using your branch, please rebase it against the current master (or other target branch in the main project).
-
When writing a commit message please follow these conventions, if you are fixing an existing issue please add
Fixes gh-XXXXat the end of the commit message (where XXXX is the issue number).
Spring Cloud Build comes with a set of checkstyle rules. You can find them in the spring-cloud-build-tools module. The most notable files under the module are:
└── src ├── checkstyle │ └── checkstyle-suppressions.xml (3) └── main └── resources ├── checkstyle-header.txt (2) └── checkstyle.xml (1)
-
Default Checkstyle rules
-
File header setup
-
Default suppression rules
Checkstyle rules are disabled by default. To add checkstyle to your project just define the following properties and plugins.
<properties>
<maven-checkstyle-plugin.failsOnError>true</maven-checkstyle-plugin.failsOnError> (1)
<maven-checkstyle-plugin.failsOnViolation>true
</maven-checkstyle-plugin.failsOnViolation> (2)
<maven-checkstyle-plugin.includeTestSourceDirectory>true
</maven-checkstyle-plugin.includeTestSourceDirectory> (3)
</properties>
<build>
<plugins>
<plugin> (4)
<groupId>io.spring.javaformat</groupId>
<artifactId>spring-javaformat-maven-plugin</artifactId>
</plugin>
<plugin> (5)
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
</plugin>
</plugins>
<reporting>
<plugins>
<plugin> (5)
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
</plugin>
</plugins>
</reporting>
</build>
-
Fails the build upon Checkstyle errors
-
Fails the build upon Checkstyle violations
-
Checkstyle analyzes also the test sources
-
Add the Spring Java Format plugin that will reformat your code to pass most of the Checkstyle formatting rules
-
Add checkstyle plugin to your build and reporting phases
If you need to suppress some rules (e.g. line length needs to be longer), then it’s enough for you to define a file under ${project.root}/src/checkstyle/checkstyle-suppressions.xml with your suppressions. Example:
<?xml version="1.0"?>
<!DOCTYPE suppressions PUBLIC
"-//Puppy Crawl//DTD Suppressions 1.1//EN"
"https://www.puppycrawl.com/dtds/suppressions_1_1.dtd">
<suppressions>
<suppress files=".*ConfigServerApplication\.java" checks="HideUtilityClassConstructor"/>
<suppress files=".*ConfigClientWatch\.java" checks="LineLengthCheck"/>
</suppressions>
It’s advisable to copy the ${spring-cloud-build.rootFolder}/.editorconfig and ${spring-cloud-build.rootFolder}/.springformat to your project. That way, some default formatting rules will be applied. You can do so by running this script:
$ curl https://raw.githubusercontent.com/spring-cloud/spring-cloud-build/master/.editorconfig -o .editorconfig
$ touch .springformatIn order to setup Intellij you should import our coding conventions, inspection profiles and set up the checkstyle plugin. The following files can be found in the Spring Cloud Build project.
└── src ├── checkstyle │ └── checkstyle-suppressions.xml (3) └── main └── resources ├── checkstyle-header.txt (2) ├── checkstyle.xml (1) └── intellij ├── Intellij_Project_Defaults.xml (4) └── Intellij_Spring_Boot_Java_Conventions.xml (5)
-
Default Checkstyle rules
-
File header setup
-
Default suppression rules
-
Project defaults for Intellij that apply most of Checkstyle rules
-
Project style conventions for Intellij that apply most of Checkstyle rules

Go to File → Settings → Editor → Code style. There click on the icon next to the Scheme section. There, click on the Import Scheme value and pick the Intellij IDEA code style XML option. Import the spring-cloud-build-tools/src/main/resources/intellij/Intellij_Spring_Boot_Java_Conventions.xml file.

Go to File → Settings → Editor → Inspections. There click on the icon next to the Profile section. There, click on the Import Profile and import the spring-cloud-build-tools/src/main/resources/intellij/Intellij_Project_Defaults.xml file.
To have Intellij work with Checkstyle, you have to install the Checkstyle plugin. It’s advisable to also install the Assertions2Assertj to automatically convert the JUnit assertions

Go to File → Settings → Other settings → Checkstyle. There click on the + icon in the Configuration file section. There, you’ll have to define where the checkstyle rules should be picked from. In the image above, we’ve picked the rules from the cloned Spring Cloud Build repository. However, you can point to the Spring Cloud Build’s GitHub repository (e.g. for the checkstyle.xml : raw.githubusercontent.com/spring-cloud/spring-cloud-build/master/spring-cloud-build-tools/src/main/resources/checkstyle.xml). We need to provide the following variables:
-
checkstyle.header.file- please point it to the Spring Cloud Build’s,spring-cloud-build-tools/src/main/resources/checkstyle-header.txtfile either in your cloned repo or via theraw.githubusercontent.com/spring-cloud/spring-cloud-build/master/spring-cloud-build-tools/src/main/resources/checkstyle-header.txtURL. -
checkstyle.suppressions.file- default suppressions. Please point it to the Spring Cloud Build’s,spring-cloud-build-tools/src/checkstyle/checkstyle-suppressions.xmlfile either in your cloned repo or via theraw.githubusercontent.com/spring-cloud/spring-cloud-build/master/spring-cloud-build-tools/src/checkstyle/checkstyle-suppressions.xmlURL. -
checkstyle.additional.suppressions.file- this variable corresponds to suppressions in your local project. E.g. you’re working onspring-cloud-contract. Then point to theproject-root/src/checkstyle/checkstyle-suppressions.xmlfolder. Example forspring-cloud-contractwould be:/home/username/spring-cloud-contract/src/checkstyle/checkstyle-suppressions.xml.
|
Important
|
Remember to set the Scan Scope to All sources since we apply checkstyle rules for production and test sources.
|