Module 12 Challenge

Credit risk poses a classification problem that’s inherently imbalanced. This is because healthy loans easily outnumber risky loans. In this Challenge, I’ll use various techniques to train and evaluate models with imbalanced classes. I’ll use a dataset of historical lending activity from a peer-to-peer lending services company to build a model that can identify the creditworthiness of borrowers.
The data we're analyzing comes from a jupyter notebook that we'll create and import files to. We'll be using Python to run and read our data.
- [jupyter] - (https://github.com/jupyter/notebook) - Helps us run our code and get the information we need from the data listed in csv files.
In order for us to get the data we need we must import pandas, plots and the csv files we want to observe.
# Import the modules
import numpy as np
import pandas as pd
from pathlib import Path
from sklearn.metrics import balanced_accuracy_score
from sklearn.metrics import confusion_matrix
from imblearn.metrics import classification_report_imbalanced
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from imblearn.over_sampling import RandomOverSampler
import warnings
warnings.filterwarnings('ignore')-
Calculate the accuracy score of the model.
-
Generate a confusion matrix.
-
Print the classification report.
# Print the balanced_accuracy score of the model
accuracy = balanced_accuracy_score(y_test, y_pred_test2)
print(accuracy)
# Generate a confusion matrix for the model
training_matrix2 = confusion_matrix(y_test, y_pred_test2)
training_matrix2
# Print the classification report for the model
training_report2 = classification_report_imbalanced(y_test, y_pred_test2)
print(training_report2)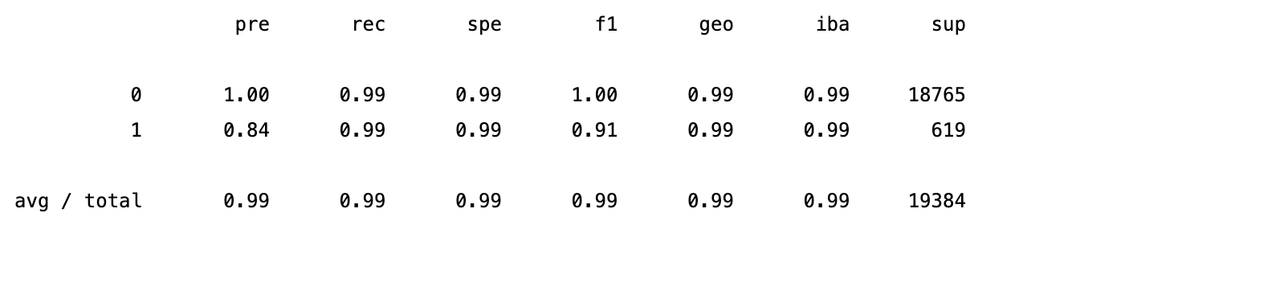
Brought to you by Elgin Braggs Jr.
MIT